Qual é o algoritmo ideal para o jogo 2048?
2 ou 4. O jogo termina quando todas as caixas são preenchidas e não existem jogadas que possam juntar as peças, ou você cria uma peça com um valor de 2048.
Primeiro, preciso de seguir uma estratégia bem definida para alcançar o objectivo. Então, pensei em a escrever um programa para isso.
o meu algoritmo actual:
while (!game_over) {
for each possible move:
count_no_of_merges_for_2-tiles and 4-tiles
choose the move with a large number of merges
}
O que estou a fazer é em qualquer altura, vou tentar juntar as peças com os valores 2 e 4, isto é, tento ter as peças 2 e 4, o mínimo possível. Se eu tentar desta forma, todos os outros azulejos foram automaticamente mesclados e a estratégia parece boa.
14 answers
Desenvolvi uma AI 2048 usandoa optimização do expectimax , em vez da pesquisa minimax usada pelo algoritmo de @ovolve. A ia simplesmente realiza a maximização sobre todos os movimentos possíveis, seguido pela expectativa sobre todas as desova de azulejos possíveis (ponderada pela probabilidade das azulejos, ou seja, 10% para um 4 e 90% para um 2). Tanto quanto sei, não é possível podar a otimização de expectimax (exceto para remover ramos que são extremamente improváveis), e assim o algoritmo usado é um cuidadosamente optimizada Busca por força bruta.
Desempenho
A IA na sua configuração predefinida (profundidade máxima de pesquisa de 8) leva de 10m a 200m para executar um movimento, dependendo da complexidade da posição do tabuleiro. Em testes, a IA atinge uma taxa média de movimento de 5-10 movimentos por segundo ao longo de um jogo inteiro. Se a profundidade de pesquisa estiver limitada a 6 movimentos, a IA pode executar facilmente 20 + movimentos por segundo, o que torna interessante para alguns a ver.
Para avaliar o desempenho de Pontuação da IA, corri a IA 100 vezes (ligado ao jogo do navegador via controle remoto). Para cada peça, Aqui estão as proporções de jogos em que essa peça foi alcançada pelo menos uma vez:
2048: 100%
4096: 100%
8192: 100%
16384: 94%
32768: 36%
A pontuação mínima em todas as corridas foi de 124024; a pontuação máxima alcançada foi de 794076. = = Ligações externas = = A IA nunca falhou em obter a telha 2048 (por isso, nunca perdeu o jogo, mesmo uma vez em 100 jogos); de facto, alcançou a 8192 Azulejo pelo menos uma vez em cada corrida!
Aqui está a imagem da melhor execução:
Implementação
A minha abordagem codifica todo o tabuleiro (16 entradas) como um único inteiro de 64 bits (onde as peças são os blocos de nybbles, ou seja, os blocos de 4 bits). Em uma máquina de 64 bits, isso permite que todo o tabuleiro seja passado em um único registrador de máquina.
Mudança de bits as operações são usadas para extrair linhas e colunas individuais. Uma única linha ou coluna é uma quantidade de 16 bits, então uma tabela de tamanho 65536 pode codificar transformações que operam em uma única linha ou coluna. Por exemplo, os movimentos são implementados como 4 pesquisas em um precomputed "mover efeito de mesa", que descreve como cada movimento que afeta uma única linha ou coluna (por exemplo, o "mover para a direita" tabela contém a entrada "1122 -> 0023", descrevendo a forma como a linha [2,2,4,4] torna-se a linha [0,0,4,8] quando se mudou para a direito).
A pontuação também é feita com a pesquisa na tabela. As tabelas contêm pontuações heurísticas computadas em todas as linhas/colunas possíveis, e a pontuação resultante para uma placa é simplesmente a soma dos valores da tabela em cada linha e coluna.
Esta representação do Conselho, juntamente com a abordagem de pesquisa da tabela para o movimento e pontuação, permite que a IA procure um grande número de estados de jogo em um curto período de tempo (mais de 10.000.000 estados de jogo por segundo em um núcleo de meados de 2011 portatil).A pesquisa do expectimax em si é codificada como uma pesquisa recursiva que alterna entre os passos de "expectativa" (testando todos os locais e valores possíveis, e ponderando suas pontuações otimizadas pela probabilidade de cada possibilidade), e os passos de "maximização" (testando todos os movimentos possíveis e selecionando o que tem a melhor pontuação). A pesquisa em árvore termina quando vê uma posição previamente vista (usando uma tabela de transposição ), quando atinge um predefinido limite de profundidade, ou quando chega a um estado de placa que é altamente improvável (por exemplo, foi alcançado por obter 6 "4" ladrilhos em uma linha a partir da posição inicial). A profundidade de busca típica é de 4-8 movimentos.
Heurística Várias heurísticas são usadas para direcionar o algoritmo de otimização para posições favoráveis. A escolha precisa do heuristic tem um efeito enorme no desempenho do algoritmo. As várias heurísticas são ponderadas e combinadas em uma pontuação posicional, que determina que" bom " é uma determinada posição no conselho. A busca de otimização terá como objetivo maximizar a pontuação média de todas as posições possíveis do tabuleiro. A pontuação real, como mostrado pelo jogo, é NÃO usada para calcular a pontuação do tabuleiro, uma vez que é muito pesada a favor da junção de peças (quando a fusão tardia pode produzir um grande benefício). Inicialmente, usei duas heurísticas muito simples, concedendo "bónus" para quadrados abertos e para ter grandes valores na borda. Estas heurísticas muito bem, frequentemente alcançando 16384, mas nunca chegando a 32768.Petr Morávek (@xificurk) levou a minha IA e adicionou duas novas heurísticas. A primeira heurística foi uma pena por ter não-monotônicas linhas e colunas que aumentou as fileiras aumentou, garantindo que não-monotônicas linhas de pequenos números não iria afectar fortemente o placar, mas não-monotônicas linhas de grandes números de ferir o placar substancialmente. O segundo heuristic contou o número de fusões potenciais ( valores iguais) além de espaços abertos. Estas duas heurísticas serviram para empurrar o algoritmo para placas monotônicas (que são mais fáceis de fundir), e para posições de placas com muitas fusões (encorajando-o a alinhar fusões onde possível para maior efeito).
Além disso, o Petr também optimizou os pesos heuristicos usando uma estratégia de " meta-optimização "(usando um algoritmo chamado CMA-ES ), onde os próprios pesos foram ajustados para obter a maior média possível. pontuacao.
O efeito destas alterações é extremamente significativo. O algoritmo passou de alcançar a tile de 16384 em torno de 13% do tempo para alcançá-la mais de 90% do tempo, e o algoritmo começou a alcançar 32768 em 1/3 do tempo (enquanto a velha heurística nunca produziu uma tile de 32768).
Acho que ainda há espaço para melhorias na heurística. Este algoritmo definitivamente ainda não é" ideal", mas sinto que está a ficar muito perto.Isso a IA atinge o 32768 tile em mais de um terço de seus jogos é um grande marco; ficarei surpreso ao ouvir se algum jogador humano alcançou 32768 no jogo oficial (ou seja, sem usar ferramentas como savestates ou desfazer). Acho que a telha 65536 está ao alcance!
Podes tentar a ia sozinho. O código está disponível em https://github.com/nneonneo/2048-ai.Actualmente, o programa atinge cerca de 90% da taxa de vitória a correr em javascript no navegador do meu portátil, dado cerca de 100 milissegundos de tempo de reflexão por movimento, por isso, embora não perfeito (ainda! tem um bom desempenho.
Uma vez que o jogo é um espaço de Estado discreto, informação perfeita, jogo baseado em turnos como xadrez e damas, usou os mesmos métodos que foram comprovadamente para trabalhar nesses jogos, nomeadamente minimax procurar com poda alfa-beta . Uma vez que já há muita informação sobre esse algoritmo lá fora, vou apenas falar sobre as duas principais heurísticas que eu uso na função de avaliação estática e que formalizam muitas das intuições que outras pessoas expressaram aqui.Monotonicidade
Este heurístico tenta garantir que os valores das peças são todos aumentando ou diminuindo ao longo das direções esquerda/direita e para cima/para baixo. Este heurístico por si só capta a intuição que muitos outros mencionaram, de que azulejos de valor superior devem ser agrupados em um canto. Ele normalmente impedirá telhas de menor valor de ficarem órfãs e manterá o tabuleiro muito organizado, com telhas menores em cascata e preenchendo as telhas maiores. Aqui está uma imagem de uma grelha perfeitamente monotónica. Obtive isto ao gerir o algorithm with the eval function set to desconsidere the other heuristics and only consider monotonicity.
Suavidade
A heurística acima por si só tende a criar estruturas nas quais os azulejos adjacentes estão a diminuir de valor, mas, claro, para se fundirem, os azulejos adjacentes têm de ser o mesmo valor. Portanto, a suavidade heurística apenas mede a diferença de valor entre azulejos vizinhos, tentando minimizar esta contagem.
Um comentador sobre Hacker News gave an interesting formalization of this idea in terms of graph theory. Aqui está uma imagem de uma grelha perfeitamente suave, cortesia deste excelente garfo de paródia.
Peças Livres
E finalmente, há uma penalização por ter muito poucos azulejos livres, uma vez que as opções podem acabar rapidamente quando o tabuleiro de jogo fica muito apertado.
E é isso! Procurar pelo espaço do jogo, ao mesmo tempo que otimizar estes critérios, produz notavelmente desempenho. Uma vantagem para usar uma abordagem generalizada como esta ao invés de uma estratégia de movimento explicitamente codificada é que o algoritmo muitas vezes pode encontrar soluções interessantes e inesperadas. Se você vê-lo correr, ele muitas vezes vai fazer movimentos surpreendentes, mas eficazes, como de repente mudar de parede ou Canto que ele está construindo contra.Editar:
Eis uma demonstração do poder desta abordagem. Eu desapertei os valores da telha (por isso continuou depois de alcançar 2048) e aqui está o melhor resultado após oito ensaios.
EDIT: Este é um algoritmo ingênuo, modelando o processo de pensamento consciente humano, e obtém resultados muito fracos em comparação com a IA que busca Todas as possibilidades, uma vez que ele só olha uma peça à frente. Foi enviado no início da linha do tempo de resposta.
Aperfeiçoei o algoritmo e venci o jogo! Pode falhar devido à simples má sorte perto do fim (você é forçado a descer, o que você nunca deve fazer, e uma telha aparece onde seu mais alto deve estar. Tenta apenas manter o linha superior preenchida, então mover para a esquerda não quebra o padrão), mas basicamente você acaba tendo uma parte fixa e uma parte móvel para jogar. Este é o seu objectivo:
1024 512 256 128
8 16 32 64
4 2 x x
x x x x
O canto escolhido é arbitrário, você basicamente nunca pressiona uma tecla (o movimento proibido), e se você fizer, você pressiona o contrário novamente e tentar corrigi-lo. Para as peças futuras, o modelo espera sempre que a próxima peça aleatória seja uma 2 e apareça na lado oposto ao modelo atual (enquanto a primeira linha está incompleta, no canto inferior direito, uma vez concluída a primeira linha, no canto inferior esquerdo).
Aqui vai o algoritmo. Cerca de 80% ganha (parece que é sempre possível ganhar com mais técnicas de IA" profissional", eu não tenho certeza sobre isso, embora.)initiateModel();
while(!game_over)
{
checkCornerChosen(); // Unimplemented, but it might be an improvement to change the reference point
for each 3 possible move:
evaluateResult()
execute move with best score
if no move is available, execute forbidden move and undo, recalculateModel()
}
evaluateResult() {
calculatesBestCurrentModel()
calculates distance to chosen model
stores result
}
calculateBestCurrentModel() {
(according to the current highest tile acheived and their distribution)
}
 O modelo mudou devido à sorte de estar mais próximo do modelo esperado. O modelo AI está tentando alcançar é
O modelo mudou devido à sorte de estar mais próximo do modelo esperado. O modelo AI está tentando alcançar é
512 256 128 x
X X x x
X X x x
x x x x
E a corrente para lá chegar tornou-se:
512 256 64 O
8 16 32 O
4 x x x
x x x x
Os O representam espaços proibidos...
Então ele vai pressionar para a direita, em seguida, para a direita novamente, em seguida, (para a direita ou para cima, dependendo de onde o 4 criou), em seguida, vai prosseguir para completar a cadeia até que ele começa:

512 256 128 64
4 8 16 32
X X x x
x x x x

O 1024 512 256
O O O 128
8 16 32 64
4 x x x
O 1024 512 256
x x 128 128
x x x x
x x x x
Fiquei interessado na ideia de uma IA para este jogo que contémnenhuma inteligência codificada (ou seja, nenhuma heurística, funções de Pontuação, etc). A IA deve "saber" apenas as regras do jogo, e "descobrir" o jogo. Isto é em contraste com a maioria dos AIs (como os deste tópico) onde o jogo é essencialmente Força bruta dirigida por uma função de pontuação representando a compreensão humana do jogo.
Algoritmo de IA
Encontrei um simples ainda surpreendentemente bom algoritmo de jogo: para determinar a próxima jogada para um dado tabuleiro, a IA joga o jogo na memória usando movimentos aleatórios até que o jogo termine. Isto é feito várias vezes, mantendo o controle da pontuação final do jogo. Em seguida, calcula-se a pontuação final média por jogada inicial. O movimento inicial com a pontuação final média mais alta é escolhido como o próximo movimento.Com apenas 100 runs (I. E. em jogos de memória) por movimento, a IA atinge a 2048 tile 80% das vezes e o 4096 azulejo 50% das vezes. Usando 10000 runs obtém o 2048 tile 100%, 70% para o 4096 tile, e cerca de 1% para o 8192 tile.
A melhor pontuação alcançada é mostrada aqui:
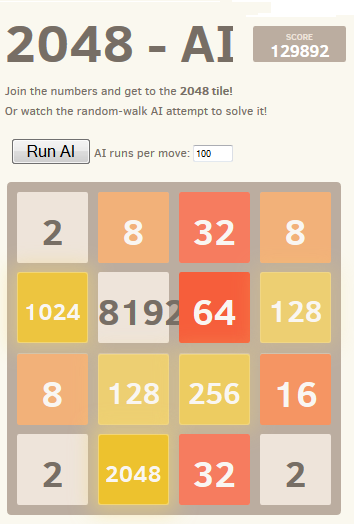
Este gráfico ilustra este ponto: a linha azul mostra a pontuação do tabuleiro após cada movimento. A linha vermelha mostra a pontuação do algoritmo Melhor de fim de jogo de execução aleatória a partir dessa posição. Em essência, os valores vermelhos estão "puxando" os valores azuis para cima em direção a eles, como eles são o melhor palpite do algoritmo. É interessante ver que a linha vermelha está apenas um pouco acima da linha azul em cada ponto, mas a linha azul continua a aumentar cada vez mais.
À procura mais tarde descobri que este algoritmo pode ser classificado como um algoritmode pura Árvore de Monte Carlo .
Implementação e Links
Primeiro criei uma versão JavaScript que pode ser vista em acção aqui . Esta versão pode executar 100's de corridas em tempo decente. Abra a consola para obter informações extra. (fonte)
Mais tarde, para brincar mais um pouco, usei a infra-estrutura do @nneonneo altamente optimizada e implementei a minha versão em C++. Esta versão permite até 100000 corridas por movimento e até 1000000 se tiver paciência. Instruções de construção fornecidas. Funciona na consola e também tem um controle remoto para reproduzir a versão web. (fonte)
Resultados
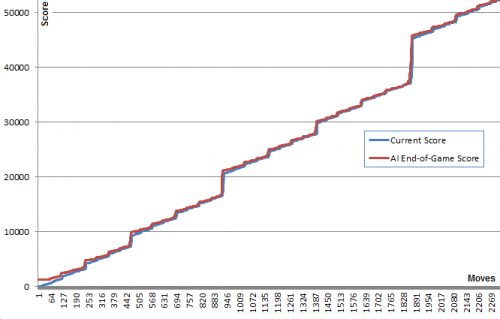
Surpreendentemente, aumentar o número de Corridas não melhora drasticamente o jogo. Parece haver um limite para esta estratégia em cerca de 80000 pontos com o 4096 azulejo e todos os menores, muito perto de alcançar o 8192 Azulejo. Aumentar o número de corridas de 100 para 100000 aumenta as probabilidades de chegar a este limite de pontuação (de 5% para 40%) mas não ultrapassar ele.Correr 10000 corridas com um aumento temporário para 1000000 perto de posições críticas conseguiu quebrar esta barreira menos de 1% das vezes alcançando uma pontuação máxima de 129892 e 8192 azulejos.
Melhorias
Depois de implementar este algoritmo, tentei muitas melhorias, incluindo a utilização das Pontuações min ou max,ou uma combinação de min,max e avg. Também tentei usar a profundidade: em vez de tentar o K corre por movimento, tentei o K move por movimento lista de um dado comprimento ("cima, cima, esquerda", por exemplo) e selecionando o primeiro movimento da lista de movimentos de melhor pontuação.
Mais tarde implementei uma árvore de pontuação que teve em conta a probabilidade condicional de ser capaz de jogar uma jogada após uma dada lista de jogadas.
No entanto, nenhuma destas ideias mostrou qualquer vantagem real sobre a simples primeira ideia. Deixei o código para estas ideias comentadas no código C++. Adicionei um mecanismo de busca profunda que aumentou o número de execução temporariamente para 1000000. quando qualquer uma das corridas conseguiu acidentalmente alcançar a peça mais alta seguinte. Isso ofereceu uma melhoria no tempo. Estaria interessado em saber se alguém tem outras ideias de melhoria que mantenham o domínio-independência da IA.2048 variantes e Clones
Só por diversão, também implementei a IA como um marcador de livros, a ligar-me aos controlos do jogo. Isto permite que a IA trabalhe com o jogo original e muitas das suas variantes . Isto é ... possível devido à natureza independente do domínio da IA. Algumas das variantes são bastante distintas, como o clone Hexagonal.Copio aqui o conteúdo de um post no meu blog
A solução que proponho é muito simples e fácil de implementar. Embora tenha atingido a pontuação de 131040. São apresentados vários parâmetros de referência das performances do algoritmo.
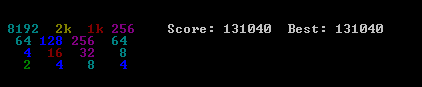
Algoritmo
Algoritmo de pontuação heurístico
A suposição sobre a qual o meu algoritmo se baseia é bastante simples: se quiser alcançar uma pontuação mais elevada, o tabuleiro deve ser mantido como o mais arrumado possível. Em particular, a configuração ideal é dada por uma ordem decrescente linear e monotônica dos valores de azulejo.
Esta intuição dar-lhe-á também o limite superior para um valor de azulejo: 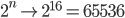
(Existe a possibilidade de alcançar a peça 131072 se a peça 4 for gerada aleatoriamente em vez da peça 2, quando necessário)
Duas formas possíveis de organizar o tabuleiro são mostradas nas seguintes imagens:
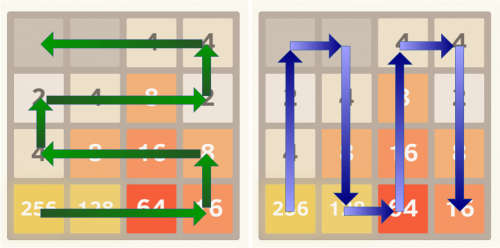
To execute a ordenação das peças numa ordem decrescente monotónica, a pontuação si calculada como a soma dos valores linearizados no tabuleiro multiplicada pelos valores de uma sequência geométrica com razão comum r
Vários caminhos lineares podem ser avaliados de uma só vez, a pontuação final será a pontuação máxima de qualquer caminho.
Regra da decisão
A regra de decisão implementada não é muito inteligente, o código em Python é apresentado aqui:
@staticmethod
def nextMove(board,recursion_depth=3):
m,s = AI.nextMoveRecur(board,recursion_depth,recursion_depth)
return m
@staticmethod
def nextMoveRecur(board,depth,maxDepth,base=0.9):
bestScore = -1.
bestMove = 0
for m in range(1,5):
if(board.validMove(m)):
newBoard = copy.deepcopy(board)
newBoard.move(m,add_tile=True)
score = AI.evaluate(newBoard)
if depth != 0:
my_m,my_s = AI.nextMoveRecur(newBoard,depth-1,maxDepth)
score += my_s*pow(base,maxDepth-depth+1)
if(score > bestScore):
bestMove = m
bestScore = score
return (bestMove,bestScore);
Parâmetro de referência
- testes T1-121-8 caminhos diferentes-r=0, 125
- testes T2-122 - 8-caminhos diferentes-r = 0, 25
- T3-132 ensaios-8-caminhos diferentes - r = 0, 5
- T4-211 testes-2-caminhos diferentes-r=0, 125
- testes T5 - 274-2-caminhos diferentes-r = 0, 25
- T6-211 testes-2-caminhos diferentes-r = 0, 5
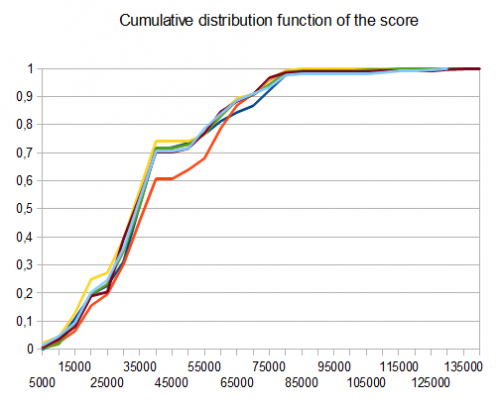
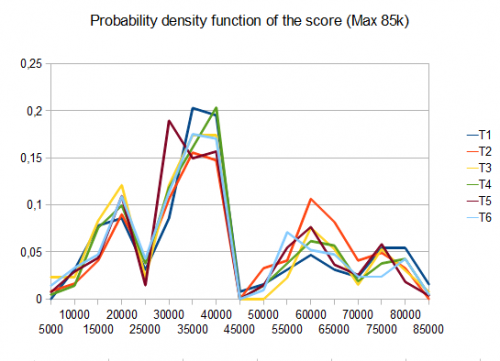
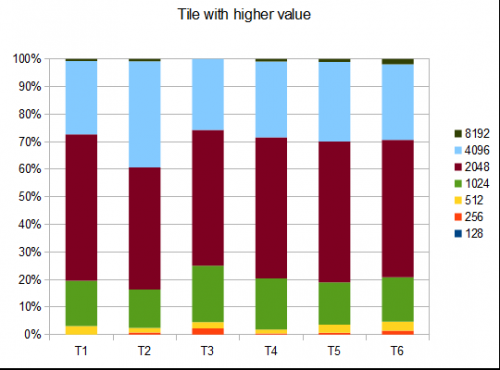
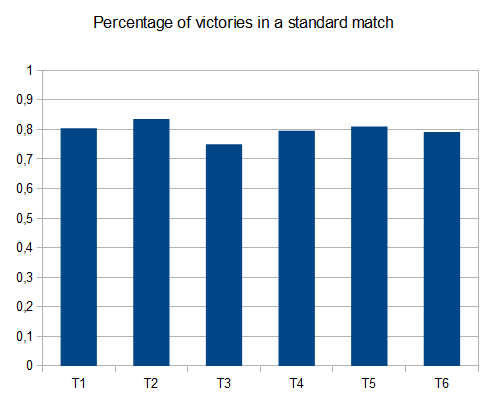
No caso do T2, quatro testes em dez geram o 4096 azulejo com uma pontuação média de 
Código
O código pode ser encontrado no GiHub na seguinte ligação: https://github.com/Nicola17/term2048-AI Baseia-se em term2048 e está escrito em Python. Vou implementar uma versão mais eficiente em C++ o mais rápido possível.
depth = free > 7 ? 1 : (free > 4 ? 2 : 3)
As pontuações das placas são calculadas com a soma ponderada do quadrado do número de azulejos livres e do número de azulejos livres. produto Ponto da grelha 2D com isto:
[[10,8,7,6.5],
[.5,.7,1,3],
[-.5,-1.5,-1.8,-2],
[-3.8,-3.7,-3.5,-3]]
Código abaixo ou jsbin :
var n = 4,
M = new MatrixTransform(n);
var ai = {weights: [1, 1], depth: 1}; // depth=1 by default, but we adjust it on every prediction according to the number of free tiles
var snake= [[10,8,7,6.5],
[.5,.7,1,3],
[-.5,-1.5,-1.8,-2],
[-3.8,-3.7,-3.5,-3]]
snake=snake.map(function(a){return a.map(Math.exp)})
initialize(ai)
function run(ai) {
var p;
while ((p = predict(ai)) != null) {
move(p, ai);
}
//console.log(ai.grid , maxValue(ai.grid))
ai.maxValue = maxValue(ai.grid)
console.log(ai)
}
function initialize(ai) {
ai.grid = [];
for (var i = 0; i < n; i++) {
ai.grid[i] = []
for (var j = 0; j < n; j++) {
ai.grid[i][j] = 0;
}
}
rand(ai.grid)
rand(ai.grid)
ai.steps = 0;
}
function move(p, ai) { //0:up, 1:right, 2:down, 3:left
var newgrid = mv(p, ai.grid);
if (!equal(newgrid, ai.grid)) {
//console.log(stats(newgrid, ai.grid))
ai.grid = newgrid;
try {
rand(ai.grid)
ai.steps++;
} catch (e) {
console.log('no room', e)
}
}
}
function predict(ai) {
var free = freeCells(ai.grid);
ai.depth = free > 7 ? 1 : (free > 4 ? 2 : 3);
var root = {path: [],prob: 1,grid: ai.grid,children: []};
var x = expandMove(root, ai)
//console.log("number of leaves", x)
//console.log("number of leaves2", countLeaves(root))
if (!root.children.length) return null
var values = root.children.map(expectimax);
var mx = max(values);
return root.children[mx[1]].path[0]
}
function countLeaves(node) {
var x = 0;
if (!node.children.length) return 1;
for (var n of node.children)
x += countLeaves(n);
return x;
}
function expectimax(node) {
if (!node.children.length) {
return node.score
} else {
var values = node.children.map(expectimax);
if (node.prob) { //we are at a max node
return Math.max.apply(null, values)
} else { // we are at a random node
var avg = 0;
for (var i = 0; i < values.length; i++)
avg += node.children[i].prob * values[i]
return avg / (values.length / 2)
}
}
}
function expandRandom(node, ai) {
var x = 0;
for (var i = 0; i < node.grid.length; i++)
for (var j = 0; j < node.grid.length; j++)
if (!node.grid[i][j]) {
var grid2 = M.copy(node.grid),
grid4 = M.copy(node.grid);
grid2[i][j] = 2;
grid4[i][j] = 4;
var child2 = {grid: grid2,prob: .9,path: node.path,children: []};
var child4 = {grid: grid4,prob: .1,path: node.path,children: []}
node.children.push(child2)
node.children.push(child4)
x += expandMove(child2, ai)
x += expandMove(child4, ai)
}
return x;
}
function expandMove(node, ai) { // node={grid,path,score}
var isLeaf = true,
x = 0;
if (node.path.length < ai.depth) {
for (var move of[0, 1, 2, 3]) {
var grid = mv(move, node.grid);
if (!equal(grid, node.grid)) {
isLeaf = false;
var child = {grid: grid,path: node.path.concat([move]),children: []}
node.children.push(child)
x += expandRandom(child, ai)
}
}
}
if (isLeaf) node.score = dot(ai.weights, stats(node.grid))
return isLeaf ? 1 : x;
}
var cells = []
var table = document.querySelector("table");
for (var i = 0; i < n; i++) {
var tr = document.createElement("tr");
cells[i] = [];
for (var j = 0; j < n; j++) {
cells[i][j] = document.createElement("td");
tr.appendChild(cells[i][j])
}
table.appendChild(tr);
}
function updateUI(ai) {
cells.forEach(function(a, i) {
a.forEach(function(el, j) {
el.innerHTML = ai.grid[i][j] || ''
})
});
}
updateUI(ai)
function runAI() {
var p = predict(ai);
if (p != null && ai.running) {
move(p, ai)
updateUI(ai)
requestAnimationFrame(runAI)
}
}
runai.onclick = function() {
if (!ai.running) {
this.innerHTML = 'stop AI';
ai.running = true;
runAI();
} else {
this.innerHTML = 'run AI';
ai.running = false;
}
}
hint.onclick = function() {
hintvalue.innerHTML = ['up', 'right', 'down', 'left'][predict(ai)]
}
document.addEventListener("keydown", function(event) {
if (event.which in map) {
move(map[event.which], ai)
console.log(stats(ai.grid))
updateUI(ai)
}
})
var map = {
38: 0, // Up
39: 1, // Right
40: 2, // Down
37: 3, // Left
};
init.onclick = function() {
initialize(ai);
updateUI(ai)
}
function stats(grid, previousGrid) {
var free = freeCells(grid);
var c = dot2(grid, snake);
return [c, free * free];
}
function dist2(a, b) { //squared 2D distance
return Math.pow(a[0] - b[0], 2) + Math.pow(a[1] - b[1], 2)
}
function dot(a, b) {
var r = 0;
for (var i = 0; i < a.length; i++)
r += a[i] * b[i];
return r
}
function dot2(a, b) {
var r = 0;
for (var i = 0; i < a.length; i++)
for (var j = 0; j < a[0].length; j++)
r += a[i][j] * b[i][j]
return r;
}
function product(a) {
return a.reduce(function(v, x) {
return v * x
}, 1)
}
function maxValue(grid) {
return Math.max.apply(null, grid.map(function(a) {
return Math.max.apply(null, a)
}));
}
function freeCells(grid) {
return grid.reduce(function(v, a) {
return v + a.reduce(function(t, x) {
return t + (x == 0)
}, 0)
}, 0)
}
function max(arr) { // return [value, index] of the max
var m = [-Infinity, null];
for (var i = 0; i < arr.length; i++) {
if (arr[i] > m[0]) m = [arr[i], i];
}
return m
}
function min(arr) { // return [value, index] of the min
var m = [Infinity, null];
for (var i = 0; i < arr.length; i++) {
if (arr[i] < m[0]) m = [arr[i], i];
}
return m
}
function maxScore(nodes) {
var min = {
score: -Infinity,
path: []
};
for (var node of nodes) {
if (node.score > min.score) min = node;
}
return min;
}
function mv(k, grid) {
var tgrid = M.itransform(k, grid);
for (var i = 0; i < tgrid.length; i++) {
var a = tgrid[i];
for (var j = 0, jj = 0; j < a.length; j++)
if (a[j]) a[jj++] = (j < a.length - 1 && a[j] == a[j + 1]) ? 2 * a[j++] : a[j]
for (; jj < a.length; jj++)
a[jj] = 0;
}
return M.transform(k, tgrid);
}
function rand(grid) {
var r = Math.floor(Math.random() * freeCells(grid)),
_r = 0;
for (var i = 0; i < grid.length; i++) {
for (var j = 0; j < grid.length; j++) {
if (!grid[i][j]) {
if (_r == r) {
grid[i][j] = Math.random() < .9 ? 2 : 4
}
_r++;
}
}
}
}
function equal(grid1, grid2) {
for (var i = 0; i < grid1.length; i++)
for (var j = 0; j < grid1.length; j++)
if (grid1[i][j] != grid2[i][j]) return false;
return true;
}
function conv44valid(a, b) {
var r = 0;
for (var i = 0; i < 4; i++)
for (var j = 0; j < 4; j++)
r += a[i][j] * b[3 - i][3 - j]
return r
}
function MatrixTransform(n) {
var g = [],
ig = [];
for (var i = 0; i < n; i++) {
g[i] = [];
ig[i] = [];
for (var j = 0; j < n; j++) {
g[i][j] = [[j, i],[i, n-1-j],[j, n-1-i],[i, j]]; // transformation matrix in the 4 directions g[i][j] = [up, right, down, left]
ig[i][j] = [[j, i],[i, n-1-j],[n-1-j, i],[i, j]]; // the inverse tranformations
}
}
this.transform = function(k, grid) {
return this.transformer(k, grid, g)
}
this.itransform = function(k, grid) { // inverse transform
return this.transformer(k, grid, ig)
}
this.transformer = function(k, grid, mat) {
var newgrid = [];
for (var i = 0; i < grid.length; i++) {
newgrid[i] = [];
for (var j = 0; j < grid.length; j++)
newgrid[i][j] = grid[mat[i][j][k][0]][mat[i][j][k][1]];
}
return newgrid;
}
this.copy = function(grid) {
return this.transform(3, grid)
}
}body {
text-align: center
}
table, th, td {
border: 1px solid black;
margin: 5px auto;
}
td {
width: 35px;
height: 35px;
text-align: center;
}<table></table>
<button id=init>init</button><button id=runai>run AI</button><button id=hint>hint</button><span id=hintvalue></span>Eu sou o autor de um controlador 2048 que pontua melhor do que qualquer outro programa mencionado neste tópico. Uma implementação eficiente do controlador está disponível em github . Em um acordo de recompra separado existe também o código utilizado para treinar a função de avaliação do Estado do controlador. O método de formação é descrito no documento .
O controlador usa a pesquisa de expectimax com uma função de avaliação de Estado aprendida do zero (SEM humanos 2048). (uma técnica de aprendizagem reforçada). A função do valor de Estado usa uma rede N-tuple , que é basicamente uma função linear ponderada dos padrões observados no tabuleiro. Envolvia mais de mil milhões de pesos , no total.
Desempenho
A 1 movimento/s: 609104 (100 Média dos Jogos)
A 10 movimentos/s: 589355 (300 média dos Jogos)
A 3-ply (ca. 1500 movimentos/s): 511759 (1000 média dos Jogos)
As estatísticas de peças para 10 movimentos/s são as seguintes:
2048: 100%
4096: 100%
8192: 100%
16384: 97%
32768: 64%
32768,16384,8192,4096: 10%
(a última linha significa ter as peças indicadas ao mesmo tempo no tabuleiro).
Para 3 camadas:
2048: 100%
4096: 100%
8192: 100%
16384: 96%
32768: 54%
32768,16384,8192,4096: 8%
Por favor, veja o código abaixo:
while( !game_over ) {
move_direction=up;
if( !move_is_possible(up) ) {
if( move_is_possible(right) && move_is_possible(left) ){
if( number_of_empty_cells_after_moves(left,up) > number_of_empty_cells_after_moves(right,up) )
move_direction = left;
else
move_direction = right;
} else if ( move_is_possible(left) ){
move_direction = left;
} else if ( move_is_possible(right) ){
move_direction = right;
} else {
move_direction = down;
}
}
do_move(move_direction);
}
Já existe uma implementação de IA para este jogo: Aqui. Excerto de README:
O algoritmo é profundidade iterativa na primeira pesquisa alfa-beta. A função de avaliação tenta manter as linhas e Colunas monotônicas (todas diminuindo ou aumentando) enquanto minimiza o número de telhas na grade.
Existe também uma discussão sobre ycombinator sobre este algoritmo que poderá achar útil.
Algoritmo
while(!game_over)
{
for each possible move:
evaluate next state
choose the maximum evaluation
}
Avaliação
Evaluation =
128 (Constant)
+ (Number of Spaces x 128)
+ Sum of faces adjacent to a space { (1/face) x 4096 }
+ Sum of other faces { log(face) x 4 }
+ (Number of possible next moves x 256)
+ (Number of aligned values x 2)
Dados Relativos À Avaliação
128 (Constant)
Esta é uma constante, usada como linha de base e para outros usos como testes.
+ (Number of Spaces x 128)
Mais espaços torna o estado mais flexível, multiplicamos por 128 (que é a mediana) uma vez que uma grelha cheia de 128 faces é um estado impossível ideal.
+ Sum of faces adjacent to a space { (1/face) x 4096 }
+ Sum of other faces { log(face) x 4 }
Aqui ainda precisamos verificar os valores empilhados, mas de uma forma menor que não interrompa os parâmetros de flexibilidade, então temos a soma de { x em [4,44]}.
+ (Number of possible next moves x 256)
Um estado é mais flexível se tiver mais liberdade de transições possíveis.
+ (Number of aligned values x 2)
Nota: as constantes podem ser ajustadas..
Apliquei a combinação convexa (tentei pesos heurísticos diferentes) de algumas funções de avaliação heurística, principalmente a partir da intuição e das referidas acima:
- monotonicidade
- Espaço Livre Disponível
No meu caso, o jogador do computador é completamente aleatório, mas mesmo assim assumi as configurações do adversário e implementei o agente do jogador AI como o jogador max.
Tenho uma grelha 4x4 para a jogar o jogo.
Observação:
Se atribuo demasiados pesos à primeira função heurística ou à segunda função heurística, ambos os casos os pontuações que o jogador de IA recebe são baixos. Eu joguei com muitas atribuições de peso possíveis para as funções heurísticas e tomar uma combinação convexa, mas muito raramente o jogador de IA é capaz de marcar 2048. Na maioria das vezes, ou pára em 1024 ou 512.
Também tentei o canto heurístico, mas por alguma razão faz os resultados. pior, alguma intuição porquê?Também, eu tentei aumentar a profundidade de busca de corte de 3 para 5 (não posso aumentá-lo mais uma vez que a busca que o espaço excede o tempo permitido, mesmo com a poda) e acrescentou mais um heurístico que olha para os valores dos azulejos adjacentes e dá mais pontos se eles são merge-able, mas ainda não sou capaz de obter 2048.
Acho que será melhor usar Expectimax em vez de minimax, mas ainda assim quero resolver este problema apenas com minimax e obter alta notas como 2048 ou 4096. Não sei se me está a escapar alguma coisa.
[[1]}abaixo a animação mostra os últimos passos do jogo jogado pelo agente de IA com o jogador do computador:
Qualquer informação será realmente muito útil, obrigado antecipadamente. (Este é o link do meu post no blog para o artigo: https://sandipanweb.wordpress.com/2017/03/06/using-minimax-with-alpha-beta-pruning-and-heuristic-evaluation-to-solve-2048-game-with-computer/)
A seguinte animação mostra os últimos passos do jogo jogado onde o agente do jogador de IA pode obter 2048 pontuações, desta vez adicionando o valor absoluto heurístico também:

As seguintes figuras mostram a árvore de jogoexplorada pelo agente AI do jogador assumindo o computador como adversário para apenas um passo:






A minha implementação do jogo difere ligeiramente do jogo actual, na medida em que uma nova peça é sempre um '2' (em vez de 90% 2 e 10% 4). E que a nova peça não é aleatória, mas sempre a primeira disponível do topo à esquerda. Esta variante também é conhecida como Det 2048 .
Como consequência, este solucionador é determinístico. Usei um algoritmo exaustivo que ... favorece as peças vazias. Ele executa muito rapidamente para a profundidade 1-4, mas na profundidade 5 ele fica bastante lento a cerca de 1 segundo por movimento.Abaixo está o código de implementação do algoritmo de resolução. A grade é representada como uma matriz de 16 comprimentos de inteiros. E a pontuação é feita simplesmente contando o número de quadrados vazios.
bestMove :: Int -> [Int] -> Int
bestMove depth grid = maxTuple [ (gridValue depth (takeTurn x grid), x) | x <- [0..3], takeTurn x grid /= [] ]
gridValue :: Int -> [Int] -> Int
gridValue _ [] = -1
gridValue 0 grid = length $ filter (==0) grid -- <= SCORING
gridValue depth grid = maxInList [ gridValue (depth-1) (takeTurn x grid) | x <- [0..3] ]
Move 4006
[2,64,16,4]
[16,4096,128,512]
[2048,64,1024,16]
[2,4,16,2]
Game Over
Fonte o código pode ser encontrado aqui: https://github.com/popovitsj/2048-haskell
Este algoritmo não é ideal para ganhar o jogo, mas é bastante óptimo em termos de desempenho e quantidade de código necessário:
if(can move neither right, up or down)
direction = left
else
{
do
{
direction = random from (right, down, up)
}
while(can not move in "direction")
}
Modele o tipo de estratégia que bons jogadores do jogo usam.
Por exemplo:
13 14 15 16
12 11 10 9
5 6 7 8
4 3 2 1
Leia os quadrados na ordem mostrada acima até que o próximo valor dos quadrados seja maior do que o actual. Isto apresenta o problema de tentar junta outra peça do mesmo valor a este quadrado.
Para resolver este problema, as suas são duas maneiras de se mover que não são deixados ou pior para cima e examinar ambas as possibilidades podem imediatamente revelar mais problemas, isto forma uma lista de dependências, cada problema que exige outro problema a ser resolvido primeiro. Acho que tenho esta corrente ou, em alguns casos, árvore de dependências internamente ao decidir o meu próximo passo, particularmente quando preso.
A telha precisa de se fundir com a vizinha, mas é muito pequeno: fundir outro vizinho com este.
Peça maior no caminho: aumente o valor de uma peça envolvente mais pequena.
Etc...
A abordagem será provavelmente mais complicada do que isto, mas não muito mais complicada. Pode ser esta mecânica na sensação de falta de pontuações, pesos, neurônios e Buscas profundas de possibilidades. A árvore das possibilidades rairly até precisa ser grande o suficiente para precisar de qualquer ramificação.