O que significa o índice agrupado e não agrupado?
tenho uma exposição limitada a DB e só usei DB como programador de aplicações. Quero saber sobre Clustered e Non clustered indexes.
Pesquisei no Google e o que encontrei foi:
um índice agrupado é um tipo especial de índice que grava o caminho os registros na tabela são fisicamente Opcao. Portanto, a tabela pode ter apenas um índice agrupado. Os nós de folhas de um índice agrupado contêm os dados pagina. Um índice não coberto é um índice tipo especial de índice a ordem lógica do índice não corresponder à ordem física armazenada de as linhas no disco. O nó de folha de a o índice não ilustrado não é constituído por: as páginas de dados. Em vez disso, a folha os nós contêm linhas de índice.
o que encontrei no SO foi quais são as diferenças entre um índice agrupado e um não agrupado?.
Alguém pode explicar isto em inglês?9 answers
Com um índice agrupado, as linhas são armazenadas fisicamente no disco na mesma ordem que o índice. Portanto, só pode haver um índice agrupado.
Com um índice não agrupado existe uma segunda lista que tem ponteiros para as linhas físicas. Você pode ter muitos índices Não agrupados, embora cada novo índice irá aumentar o tempo que leva para escrever novos registros.
É geralmente mais rápido ler a partir de um índice agrupado se quiser obter de volta todas as colunas. Você não temos de ir primeiro ao índice e depois à mesa.
Escrever numa tabela com um índice agrupado pode ser mais lento, se houver necessidade de reorganizar os dados.
Um índice agrupado significa que está a dizer à base de dados para guardar valores próximos uns dos outros no disco. Isto tem o benefício da rápida digitalização / recuperação de registros caindo em algum intervalo de valores de índice agrupados.
Por exemplo, tem duas tabelas, clientes e encomenda:
Customer
----------
ID
Name
Address
Order
----------
ID
CustomerID
Price
Se desejar obter rapidamente todas as encomendas de um determinado cliente, poderá querer criar um índice agrupado na coluna" CustomerID " da tabela de encomendas. Por aqui. registros com o mesmo CustomerID serão fisicamente armazenados perto um do outro no disco (agrupados) que acelera a sua recuperação.
P. S. O índice em CustomerID obviamente não será único, então você precisa adicionar um segundo campo para "unificar" o índice ou deixar a base de dados lidar com isso para você, mas isso é outra história.
Em relação a múltiplos índices. Você pode ter apenas um índice agrupado por tabela, porque isso define como os dados são fisicamente organizados. Se desejar um analogia, imagine uma sala grande com muitas mesas nela. Você pode colocar estas tabelas para formar várias linhas ou juntá-las todas para formar uma grande mesa de conferência, mas não ambas as maneiras ao mesmo tempo. Uma tabela pode ter outros índices, eles então apontarão para as entradas no índice agrupado que, por sua vez, vai finalmente dizer onde encontrar os dados reais.
No armazenamento orientado para a linha do servidor SQL, tanto os índices agrupados como os não obstruídos estão organizados como árvores B.
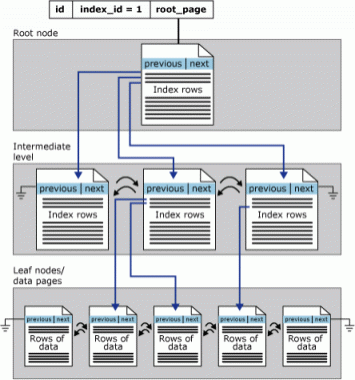
A principal diferença entre os índices agrupados e os índices Não agrupados é que o nível das folhas do índice agrupado é a tabela. Isto tem duas implicações.
- as linhas nas páginas das folhas do Índice agrupadas contêm sempre algo para cada uma das colunas (não esparsas) em a tabela (ou o valor, ou um ponteiro para o valor real).
- o índice agrupado é a cópia primária de uma tabela.
Os índices Não agrupados também podem fazer o ponto 1 usando a cláusula INCLUDE (desde o servidor sql 2005) para incluir explicitamente todas as colunas não-chave, mas são representações secundárias e há sempre outra cópia dos dados em volta (a própria tabela).
CREATE TABLE T
(
A INT,
B INT,
C INT,
D INT
)
CREATE UNIQUE CLUSTERED INDEX ci ON T(A,B)
CREATE UNIQUE NONCLUSTERED INDEX nci ON T(A,B) INCLUDE (C,D)
A,B e das páginas ao nível das folhas que contêm A,B,C,D
Só pode haver um índice agrupado por tabela, porque as linhas de dados eles mesmos podem ser classificados em apenas uma ordem.
A citação acima dos livros do servidor SQL online causa muita confusão
Na minha opinião, seria muito melhor dizer.Só pode haver um índice agrupado por tabela, porque as linhas de nível das folhas do índice agrupado são as linhas da tabela.
A citação dos livros online não está incorrecta, mas deve ficar claro que a "ordenação" dos índices Não agrupados e agrupados não é lógica e não física. Se você ler as páginas ao nível da folha, seguindo a lista vinculada e ler as linhas na página na ordem de disposição de fenda, então você vai ler as linhas de índice em ordem ordenada, mas fisicamente as páginas não podem ser ordenadas. A crença comum de que com um índice agrupado as linhas são sempre armazenadas fisicamente no disco na mesma ordem que o índice chave é falso.
Esta seria uma implementação absurda. Por exemplo, se uma linha é inserida no meio de um servidor de tabela SQL de 4GB Não tem de copiar 2GB de dados no ficheiro para criar espaço para a linha introduzida de novo . Em vez disso, ocorre uma divisão de páginas. Cada página, ao nível das folhas, de índices agrupados e não agrupados, tem o endereço (File:Page) da página seguinte e da página anterior na chave lógica ordem. Estas páginas não precisam ser contíguas ou em ordem chave.
Por exemplo, a cadeia de páginas ligadas pode ser 1:2000 <-> 1:157 <-> 1:7053
Quando uma divisão de páginas acontece, uma nova página é atribuída a partir de qualquer ponto do filegroup (quer de uma extensão mista, para tabelas pequenas, quer de uma extensão uniforme não vazia pertencente a esse objecto ou de uma extensão uniforme recém-atribuída). Isto pode nem estar no mesmo ficheiro se o grupo de ficheiros contiver mais do que um.
O grau em que a ordem lógica e a contiguidade difere da versão física idealizada é o grau de fragmentação lógica.
Em um banco de dados recém-criado com um único arquivo eu corri o seguinte.
CREATE TABLE T
(
X TINYINT NOT NULL,
Y CHAR(3000) NULL
);
CREATE CLUSTERED INDEX ix
ON T(X);
GO
--Insert 100 rows with values 1 - 100 in random order
DECLARE @C1 AS CURSOR,
@X AS INT
SET @C1 = CURSOR FAST_FORWARD
FOR SELECT number
FROM master..spt_values
WHERE type = 'P'
AND number BETWEEN 1 AND 100
ORDER BY CRYPT_GEN_RANDOM(4)
OPEN @C1;
FETCH NEXT FROM @C1 INTO @X;
WHILE @@FETCH_STATUS = 0
BEGIN
INSERT INTO T (X)
VALUES (@X);
FETCH NEXT FROM @C1 INTO @X;
END
Depois, verificou a disposição da página com
SELECT page_id,
X,
geometry::Point(page_id, X, 0).STBuffer(1)
FROM T
CROSS APPLY sys.fn_PhysLocCracker( %% physloc %% )
ORDER BY page_id
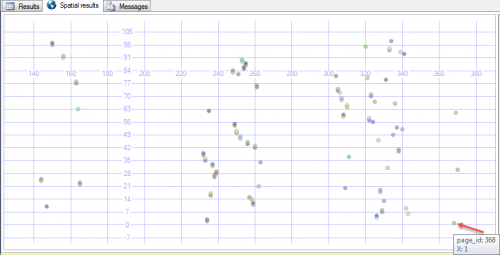
A fragmentação pode ser reduzida ou eliminada através da reconstrução ou reorganização um índice para aumentar a correlação entre a ordem lógica e a ordem física.
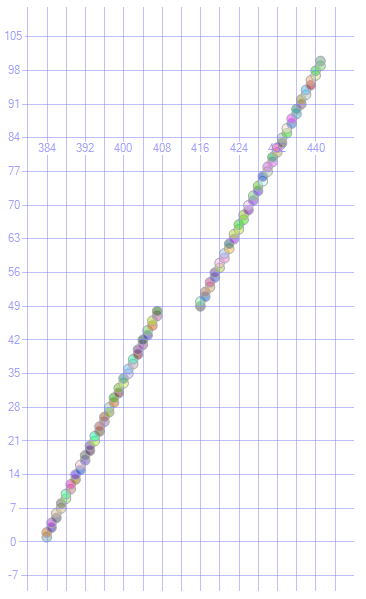
Depois de correr
ALTER INDEX ix ON T REBUILD;
Tenho o seguinte
Se a tabela não tem índice agrupado é chamado de heap.
Índices Não agrupados podem ser construídos em heap ou em um índice agrupado. Eles sempre contêm um localizador de linha de volta para a tabela base. No caso de um heap este é um identificador de linha física (rid) e consiste de três componentes (arquivo:Página:Fenda). Em the case of a Clustered index the row locator is logical (the clustered index key).
Para este último caso, se o índice não agrupado já incluir naturalmente a(s) coluna (s) da chave IC, quer como colunas da chave NCI quer INCLUDE-d, então nada é adicionado. Caso contrário, a(s) coluna (s) Chave (s) de IC em falta são acrescentadas silenciosamente ao NCI.
O servidor SQL garante sempre que as colunas chave são únicas para ambos os tipos de índice. O mecanismo em que isso é aplicado para índices não declarados como unique differs between the two index types however.
Os índices agrupados obtêm um uniquifier adicionado para todas as linhas com valores-chave que duplicam uma linha existente. Isto é apenas um inteiro ascendente.
Para os índices Não agrupados não declarados como servidor SQL único, adiciona silenciosamente o localizador da linha à chave de índice não agrupada. Isto se aplica a todas as linhas, não apenas aquelas que são realmente duplicadas.
A nomenclatura agrupada contra a nomenclatura não agrupada também é usada para o armazenamento de colunas. Index. The paper Enhancements to SQL Server Column Stores states
Embora os dados da coluna de armazenamento não estejam realmente "agrupados" em qualquer chave, nós decidiu manter a tradicional Convenção SQL Server de referência para o índice primário como um índice agrupado.
ÍNDICE AGRUPADO
Se você entrar em uma biblioteca pública, você vai descobrir que os livros estão todos dispostos em uma ordem particular (provavelmente o sistema Decimal de Dewey, ou DDS). Isto corresponde ao "índice agrupado" dos livros. Se o DDS# para o livro que você quer fosse {[[0]}, você começaria por localizar a linha de estantes de livros que é ou algo parecido. (This endcap sign at the end of the stack corresponds to an "intermediate node" in the index.) Eventualmente você iria perfurar até a prateleira específica rotulada {[[2]}, então você iria digitalizar até que você encontrou o livro com o DDS# especificado, e nesse ponto você encontrou o seu livro.
ÍNDICE NÃO AGRUPADO
Mas se não tivesses entrado na biblioteca com o DDS do teu livro memorizado, precisarias de um segundo índice para te ajudar. Nos velhos tempos você encontraria na frente da biblioteca um maravilhoso escritório de gavetas conhecido como o "catálogo de cartões". Nele estavam milhares de cartões 3x5 -- um para cada livro, ordenados por ordem alfabética (por título, talvez). Isto corresponde ao "índice não agrupado" . Estes catálogos de cartões foram organizados em uma estrutura hierárquica, de modo que cada gaveta seria rotulada com a gama de cartões que continha (Ka - Kl, por exemplo; ou seja, o "nó intermediário"). Mais uma vez, você faria perfure até encontrar o seu livro, mas em Este caso, uma vez que o tenha encontrado (i. e., O "nó folha"), não tem o livro em si, mas apenas uma carta com um índice (O DDS#) com o qual poderia encontrar o livro real no índice agrupado.
É claro que nada impediria o bibliotecário de fotocopiar todos os cartões e separá-los numa ordem diferente num catálogo de cartões separado. (Tipicamente, havia pelo menos dois desses catálogos: um classificado pelo autor nome, e um pelo título.) Em princípio, você poderia ter tantos desses índices "Não agrupados" como você quer.
Veja abaixo algumas características dos índices agrupados e não agrupados:
Índices Agrupados
- Os índices agrupados São índices que identificam unicamente as linhas numa tabela SQL. Todas as tabelas podem ter exactamente um índice agrupado.
- você pode criar um índice agrupado que cobre mais de uma coluna. Por exemplo:
create Index index_name(col1, col2, col.....). - por omissão, uma coluna com uma chave primária já tem um índice agrupado.
Não agrupados Índices
- Os índices Não agrupados são como índices simples. Eles são apenas usados para recuperação rápida de dados. Não tenho a certeza de ter dados únicos.
Uma regra não técnica muito simples seria que os índices agrupados são geralmente usados para a sua chave primária (ou, pelo menos, uma coluna única) e que os não agrupados são usados para outras situações (talvez uma chave estrangeira). De facto, o servidor SQL irá, por omissão, criar um índice agrupado na(S) Sua (s) coluna (s) Chave (s) primária (AIS). Como você terá aprendido, o índice agrupado relaciona-se com a forma como os dados são ordenados fisicamente no disco, o que significa que é uma boa escolha geral para a maioria das situações.
Índice Agrupado
Um índice agrupado determina a ordem física dos dados numa tabela.Por esta razão, uma tabela tem apenas 1 índice agrupado.
Como "dicionário" não há necessidade de qualquer outro índice, o seu Índice já de acordo com as palavras
Índice Não Coberto
Um índice não agrupado é análogo a um índice num livro.Os dados são armazenados em um único lugar. o o índice é armazenado em outro lugar e o índice tem ponteiros para o local de armazenamento do dado.Por esta razão, uma tabela tem mais de 1 índice não coberto.
Como "livro de química" para olhar, há um índice separado para apontar a localização do capítulo e no "fim" há outro índice que aponta a localização das palavras comuns
Índice Agrupado
Os índices agrupados ordenam e armazenam as linhas de dados na tabela ou vista com base nos seus valores-chave. Estas são as colunas incluídas na definição do Índice. Pode haver apenas um índice agrupado por tabela, porque as próprias linhas de dados podem ser ordenadas em apenas uma ordem.
A única altura em que as linhas de dados de uma tabela são armazenadas em ordem ordenada é quando a tabela contém um índice agrupado. Quando uma tabela tem um índice agrupado, a tabela é chamada de mesa reunida. Se uma tabela não tem índice agrupado, suas linhas de dados são armazenadas em uma estrutura não ordenada chamada de heap.
Não obstruído
Os índices não reclassificados têm uma estrutura separada das linhas de dados. Um índice não-resumido contém os valores-chave do índice não-resumido e cada entrada de valor-chave tem um ponteiro para a linha de dados que contém o valor-chave. O ponteiro de uma linha de índice em um índice não obstruído para uma linha de dados é chamado de um localizador de linha. A estrutura da linha Localizador depende se as páginas de dados são armazenadas em um heap ou em uma tabela agrupada. Para um heap, um localizador de linha é um ponteiro para a linha. Para uma tabela agregada, o localizador de linha é a chave de índice agregada.
Pode adicionar colunas não-chave ao nível das folhas do índice não-resumido para ultrapassar os limites das chaves de índice existentes e executar consultas totalmente cobertas, indexadas. Para mais informações, consulte Criar índices com as colunas incluídas. Para mais pormenores sobre os limites da tabela de índices, ver capacidade máxima Especificações para o servidor SQL.
Se o ficheiro que contém os registos for sequencialmente ordenado, um índice de agrupamento é um índice cuja chave de pesquisa também define a ordem sequencial do ficheiro. Índices de Clustering também são chamados índices primários; o termo índice primário pode parecer denotar um índice em uma chave primária, mas tais índices podem de fato ser construídos em qualquer chave de busca. A chave de busca de um índice de clustering é muitas vezes a chave primária, embora isso não seja necessariamente assim. Índices cuja chave de pesquisa especifica uma ordem diferente da ordem sequencial do arquivo são chamados índices não-clustering, ou índices secundários. Os Termos " agrupados " e "não obstruídos "são frequentemente utilizados em vez de" agrupados" e " não obstruídos."