Como posso analisar o código C++ a correr no Linux?
Eu tenho uma aplicação em C++, em execução no Linux, que estou em processo de otimização. Como posso identificar quais áreas do meu código estão a correr lentamente?
19 answers
Se o teu objectivo é usar um profiler, usa um dos sugeridos.
No entanto, se você está com pressa e pode interromper manualmente o seu programa sob o depurador enquanto ele está sendo subjetivamente lento, há uma maneira simples de encontrar problemas de desempenho. Pare várias vezes, e cada vez olhe para a pilha de chamadas. Se há algum código que está desperdiçando alguma porcentagem do Tempo, 20% ou 50% ou o que quer que, essa é a probabilidade que você vai pegá-lo no agir em cada amostra. Então, essa é aproximadamente a porcentagem de amostras em que você vai vê-lo. Não são necessárias suposições educadas. Se você tem um palpite sobre qual é o problema, isso vai provar ou refutar.Pode ter vários problemas de desempenho de tamanhos diferentes. Se você limpar qualquer um deles, os restantes terão uma porcentagem maior, e será mais fácil de detectar, em passes subsequentes. Este efeito de ampliação , Quando agravado por vários problemas, pode levar a fatores de aceleração realmente massiva.
Caveat : Os programadores tendem a ser céticos desta técnica a menos que eles mesmos a tenham usado. Eles dirão que os profilers lhe dão esta informação, mas isso só é verdade se eles provarem toda a pilha de chamadas, e então deixá-lo examinar um conjunto aleatório de amostras. (Os resumos são onde a visão está perdida.) Os gráficos de chamadas não lhe dão a mesma informação, porque
-
Eles não resumem as instruções. nível, e
Eles dão resumos confusos na presença de recursão.
Eles também vão dizer que ele só funciona em programas de brinquedo, quando na verdade ele funciona em qualquer programa, e parece funcionar melhor em programas maiores, porque eles tendem a ter mais problemas para encontrar. Eles dirão que às vezes encontra coisas que não são problemas, mas isso só é verdade se você vir algo uma vez . Se você vê um problema em mais de uma amostra, é real.
P. S. Isso também pode ser feito em programas multi-thread se houver uma maneira de coletar amostras de pilha de chamadas do thread pool em um ponto no tempo, como há em Java.
P. P. S Como uma generalidade aproximada, quanto mais camadas de abstração você tem em seu software, mais provável você é de descobrir que essa é a causa de problemas de desempenho (e a oportunidade de obter speedup).
Adicionado : pode não ser óbvio, mas a técnica de amostragem da pilha funciona igualmente bem em a presença da recursão. A razão é que o tempo que seria salvo pela remoção de uma instrução é aproximado pela fração de amostras que a contêm, independentemente do número de vezes que ela pode ocorrer dentro de uma amostra.
Outra objeção que ouço muitas vezes é: "vai parar em algum lugar Aleatório, e vai perder o verdadeiro problema ". Isto vem de ter um conceito prévio de qual é o verdadeiro problema. Uma propriedade chave dos problemas de desempenho é que eles desafiam aspiracao. A amostragem diz que algo é um problema, e sua primeira reação é descrença. Isso é natural, mas você pode ter certeza se ele encontra um problema é real, e vice-versa.
Adicionado : Deixe - me fazer uma explicação Bayesiana de como funciona. Suponha que há alguma instrução I (chamada ou não) que está na pilha de chamada alguma fração f do tempo (e assim custa tanto). Por simplicidade, suponha que não sabemos o que é f, mas suponha que seja 0.1, 0.2, 0.3, ... 0.9, 1.0, e a probabilidade prévia de cada uma dessas possibilidades é 0.1, então todos esses custos são igualmente prováveis a priori.
Então suponha que pegamos apenas 2 amostras de pilha, e vemos instruções I em ambas as amostras, observação designada o=2/2. Isto nos dá novas estimativas da frequência f de I, de acordo com isto:
Prior
P(f=x) x P(o=2/2|f=x) P(o=2/2&&f=x) P(o=2/2&&f >= x) P(f >= x | o=2/2)
0.1 1 1 0.1 0.1 0.25974026
0.1 0.9 0.81 0.081 0.181 0.47012987
0.1 0.8 0.64 0.064 0.245 0.636363636
0.1 0.7 0.49 0.049 0.294 0.763636364
0.1 0.6 0.36 0.036 0.33 0.857142857
0.1 0.5 0.25 0.025 0.355 0.922077922
0.1 0.4 0.16 0.016 0.371 0.963636364
0.1 0.3 0.09 0.009 0.38 0.987012987
0.1 0.2 0.04 0.004 0.384 0.997402597
0.1 0.1 0.01 0.001 0.385 1
P(o=2/2) 0.385
A última coluna diz que, por exemplo, a probabilidade que f > = 0, 5 é 92%, acima da suposição anterior de 60%.
Prior
P(f=x) x P(o=2/2|f=x) P(o=2/2&& f=x) P(o=2/2&&f >= x) P(f >= x | o=2/2)
0.001 1 1 0.001 0.001 0.072727273
0.001 0.9 0.81 0.00081 0.00181 0.131636364
0.001 0.8 0.64 0.00064 0.00245 0.178181818
0.001 0.7 0.49 0.00049 0.00294 0.213818182
0.001 0.6 0.36 0.00036 0.0033 0.24
0.001 0.5 0.25 0.00025 0.00355 0.258181818
0.001 0.4 0.16 0.00016 0.00371 0.269818182
0.001 0.3 0.09 0.00009 0.0038 0.276363636
0.001 0.2 0.04 0.00004 0.00384 0.279272727
0.991 0.1 0.01 0.00991 0.01375 1
P(o=2/2) 0.01375
Agora diz P(f >= 0.5) é 26%, acima da suposição anterior de 0,6%. Então Bayes nos permite atualizar nossa estimativa do custo provável de I. Se a quantidade de dados é pequena, não nos diz com precisão Qual é o custo, apenas que é grande o suficiente para valer a pena consertar.
(number of hits + 1) / (number of tries + 2) = (2+1)/(2+2) = 75%.
(A chave é que vemos I mais de uma vez. Se só o virmos uma vez, isso não nos diz muito excepto que f > 0.)
Então, mesmo um pequeno número de amostras pode nos dizer muito sobre o custo das instruções que vê. (E irá vê-los com uma frequência, em média, proporcional ao seu custo. Se forem colhidas amostras n e f for o custo, então I aparecerá nas amostras nf+/-sqrt(nf(1-f)). Exemplo, n=10, f=0.3, Isto são amostras de 3+/-1.4)
Adicionado: para dar uma ideia intuitiva da diferença entre a medição e a recolha aleatória de amostras:
Existem profilers agora que a amostra da pilha, mesmo no tempo do relógio de parede, mas o que sai é medições (ou caminho quente, ou ponto quente, do qual um "gargalo" pode facilmente esconder). O que eles não lhe mostram (e eles facilmente poderiam) é as amostras reais eles mesmos. E se seu objetivo é encontraro gargalo, o número deles que você precisa ver é, em média , 2 dividido pela fração de tempo que leva.
Por isso, se demorar 30% do tempo, 2%.3 = 6,7 amostras, em média, Irão mostrá - lo, e o talvez 20 amostras mostrem 99,2%.

A medição é horizontal; diz-lhe qual a fracção de tempo que as rotinas específicas levam. A amostragem é vertical. Se houver alguma maneira de evitar o que todo o programa está fazendo nisso momento, e se você vê isso em uma segunda amostra , você encontrou o gargalo. Isso é o que faz a diferença - ver toda a razão para o tempo que está sendo gasto, não apenas quanto.
Pode utilizar Valgrind com as seguintes opções
valgrind --tool=callgrind ./(Your binary)
Irá gerar um ficheiro chamado callgrind.out.x. Poderá então usar a ferramenta kcachegrind para ler este ficheiro. Ele lhe dará uma análise gráfica de coisas com resultados como quais linhas custam quanto.
Não se esqueça de adicionar -pg à compilação antes de traçar o perfil:
cc -o myprog myprog.c utils.c -g -pg
Pergunta relacionada aqui.
Algumas outras palavras se gprof não fizer o trabalho por ti: Valgrind , Intel VTune , Sun DTrace.
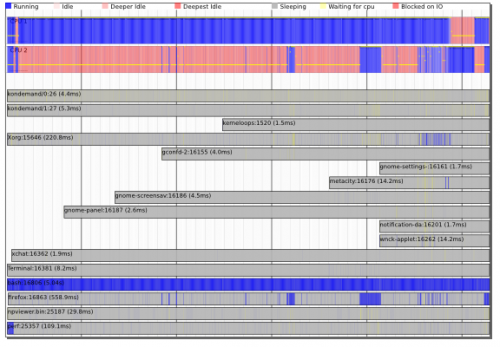
Os kernels mais recentes (por exemplo, os kernels mais recentes do Ubuntu) vêm com as novas ferramentas 'perf' ({[[0]}) AKA perf_events .
Estes vêm com perfis de amostragem clássicos ( man-page) bem como o impressionante timechart {[[4]}!
O importante é que estas ferramentas podem ser análise de perfis do sistema e não apenas processamento de análise - elas podem mostrar a interacção entre threads, processos e kernel e permitir-lhe compreender a calendarização e as dependências I/O entre processos.
Eu usaria o Valgrind e o Callgrind como base para o meu conjunto de ferramentas de análise. O que é importante saber é que Valgrind é basicamente uma máquina Virtual:
Callgrind é um profiler baseado nisso. O principal benefício é que você não tem que executar sua aplicação por horas para obter resultados confiáveis. Mesmo um segundo de corrida é suficiente para ficar sólido, resultados confiáveis, porque Callgrind é umnão-sondador profiler. Outra ferramenta construída sobre o Valgrind é Massif. Uso-o para analisar o uso de memória. Funciona muito bem. O que ele faz é que ele lhe dá fotos do uso da memória -- informações detalhadas que contêm qual porcentagem de memória, E quem a colocou lá. Essas informações estão disponíveis em diferentes pontos do tempo de execução da aplicação.(wikipedia) Valgrind é em essência um virtual máquina que utiliza o just-in-time (JIT) técnicas de compilação, incluindo: recompilação dinâmica. Nada de o programa original é executado directamente no processador hospedeiro. Em vez disso, Valgrind primeiro traduz o programa em uma forma temporária, mais simples conhecer Representação Intermédia (IR), que é um processador neutro, Forma de SSA. Após a conversão, uma ferramenta (ver abaixo) é livre de fazer quaisquer que sejam as transformações que gostaria no IR, antes de Valgrind traduzir o IR de volta para o código da máquina e permite o processador do hospedeiro executa-o.
A resposta para executar valgrind --tool=callgrind não está completamente completa sem algumas opções. Nós geralmente não queremos traçar o perfil de 10 minutos de tempo de startup lento sob Valgrind e quer fazer o perfil do nosso programa quando ele está fazendo alguma tarefa.
valgrind --tool=callgrind --dump-instr=yes -v --instr-atstart=no ./binary > tmp
callgrind_control -i on
callgrind_control -k
kcachegrind callgrind.out.*
Eu recomendo na próxima janela para clicar no cabeçalho da coluna "Self", caso contrário ele mostra que" main () " é a tarefa mais demorada. "Self" mostra o quanto cada função em si levou tempo, não junto com dependentes.
Tenho usado o Gprof nos últimos dias e já encontrei três limitações significativas, uma das quais não vi documentadas em mais nenhum lugar (ainda):
Ele não funciona corretamente em código multi-threaded, a menos que você use um workaround
O grafo de chamada fica confuso por ponteiros de função. Exemplo: eu tenho uma função chamada
multithread()que me permite multi-thread uma função especificada sobre um array especificado (ambos passados como argumentos). No entanto, o Gprof vê todas as chamadas paramultithread()como equivalentes para fins de computação do tempo gasto em crianças. Uma vez que algumas funções que passo paramultithread()levam muito mais tempo do que outras, Os meus gráficos de chamadas são inúteis. (Para aqueles que se perguntam se threading é o problema aqui: Não,multithread()pode opcionalmente, e fez neste caso, executar tudo sequencialmente na linha de chamada apenas).Diz aqui que"... o os números de chamadas são calculados por Contagem, não por amostragem. São completamente precisos...". No entanto, eu acho meu grafo de chamada me dando 5345859132+784984078 como estatísticas de chamada para a minha função mais Chamada, onde o primeiro número é suposto ser chamadas diretas, e as segundas chamadas recursivas (que são todas de si mesma). Como isso implicava que eu tinha um bug, eu coloquei contadores longos (64-bit) no código e fiz a mesma corrida novamente. Minhas contagens: 5345859132 direto, e 78094395406 chamadas auto-recursivas. Existem muitos dígitos lá, então eu vou apontar as chamadas recursivas que eu medi São 78 bilhões, versus 784m do Gprof: um fator de 100 diferentes. Ambas as corridas eram código único e não otimizado, um compilado
-ge o outro-pg.
Este era o GNU Gprof (GNU Binutils Para Debian) 2.18.0. 20080103 executando abaixo do Debian Lenny de 64 bits, se isso ajudar alguém.
Usar o Valgrind, o callgrind e o kcachegrind:
valgrind --tool=callgrind ./(Your binary)
Gera callgrind.as.x. leia com kcachegrind.
Utilizar gprof (add-pg):
cc -o myprog myprog.c utils.c -g -pg
(não é muito bom para multi-threads, ponteiros de função)
Usar o google-perftools:
Utiliza a amostragem Temporal, detectam-se estrangulamentos I / O e CPU.
Intel VTune é o melhor (gratuito para fins educacionais).
Outros: substituído por AMD CodeXL), OProfile,' perf ' tools (apt-get install linux-tools)
Levantamento das técnicas de análise de perfis em C++: gprof vs valgrind vs perf vs gperftools
Nesta resposta, vou usar várias ferramentas diferentes para analisar alguns programas de teste muito simples, a fim de comparar concretamente como essas ferramentas funcionam.
O seguinte programa de testes é muito simples e faz o seguinte:
-
mainchamadasfastemaybe_slow3 vezes, uma das chamadasmaybe_slowsendo lentaA chamada lenta de
maybe_slowé 10x mais longo, e domina o tempo de execução se considerarmos as chamadas para a função Infantilcommon. Idealmente, a ferramenta de análise será capaz de nos indicar a chamada lenta específica. -
Ambos
fastemaybe_slowchamamcommon, o que explica a maior parte da execução do programa -
A interface do programa é:
./main.out [n [seed]]E o programa faz loops no total.
seedé só para obter uma saída diferente sem afectar execucao.
#include <inttypes.h>
#include <stdio.h>
#include <stdlib.h>
uint64_t __attribute__ ((noinline)) common(uint64_t n, uint64_t seed) {
for (uint64_t i = 0; i < n; ++i) {
seed = (seed * seed) - (3 * seed) + 1;
}
return seed;
}
uint64_t __attribute__ ((noinline)) fast(uint64_t n, uint64_t seed) {
uint64_t max = (n / 10) + 1;
for (uint64_t i = 0; i < max; ++i) {
seed = common(n, (seed * seed) - (3 * seed) + 1);
}
return seed;
}
uint64_t __attribute__ ((noinline)) maybe_slow(uint64_t n, uint64_t seed, int is_slow) {
uint64_t max = n;
if (is_slow) {
max *= 10;
}
for (uint64_t i = 0; i < max; ++i) {
seed = common(n, (seed * seed) - (3 * seed) + 1);
}
return seed;
}
int main(int argc, char **argv) {
uint64_t n, seed;
if (argc > 1) {
n = strtoll(argv[1], NULL, 0);
} else {
n = 1;
}
if (argc > 2) {
seed = strtoll(argv[2], NULL, 0);
} else {
seed = 0;
}
seed += maybe_slow(n, seed, 0);
seed += fast(n, seed);
seed += maybe_slow(n, seed, 1);
seed += fast(n, seed);
seed += maybe_slow(n, seed, 0);
seed += fast(n, seed);
printf("%" PRIX64 "\n", seed);
return EXIT_SUCCESS;
}
Gprof
O Gprof requer recompilar o software com instrumentação, e também usa uma abordagem de amostragem juntamente com essa instrumentação. Portanto, atinge um equilíbrio entre precisão (amostragem nem sempre é totalmente precisa e pode saltar funções) e desaceleração da execução (instrumentação e amostragem são técnicas relativamente rápidas que não atrasam muito a execução).
O Gprof é incorporado no GCC / binutils, então tudo que temos que fazer é compilar com a opção -pg para ativar o gprof. Em seguida, executamos o programa normalmente com um parâmetro CLI tamanho que produz uma execução de duração razoável de alguns segundos (10000):
gcc -pg -ggdb3 -O3 -std=c99 -Wall -Wextra -pedantic -o main.out main.c
time ./main.out 10000
gcc -pg -ggdb3 -O0 -std=c99 -Wall -Wextra -pedantic -o main.out main.c
./main.out 10000
Primeiro, time diz-nos que o tempo de execução com e sem -pg foi o mesmo, o que é grande: Sem Desaceleração! No entanto, já vi relatos de desacelerações 2x - 3x em software complexo, por exemplo como mostrado neste bilhete.
Porque compilamos com -pg, executar o programa produz um ficheiro gmon.out contendo os dados de análise.
Podemos observar que Arquivo graficamente com gprof2dot como perguntado em: é possível obter uma representação gráfica do gprof resultados?
sudo apt install graphviz
python3 -m pip install --user gprof2dot
gprof main.out > main.gprof
gprof2dot < main.gprof | dot -Tsvg -o output.svg
Aqui, a ferramenta gprof lê a gmon.out informação de traço, e gera um relatório legível em main.gprof, que gprof2dot então lê para gerar um gráfico.
A fonte do gprof2dot é: https://github.com/jrfonseca/gprof2dot
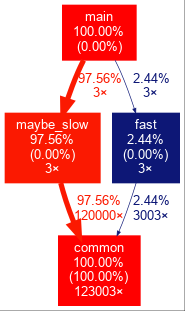
Observamos o seguinte para a execução -O0:
E para a -O3 corrida:

A saída de -O0 é bonita. muito auto-explicativo. Por exemplo, ele mostra que o 3 maybe_slow chama e seu filho chamadas levar até 97.56% do total de tempo de execução, apesar de execução de maybe_slow em si, sem filhos contas 0.00% do tempo total de execução, por exemplo, quase todo o tempo gasto nessa função foi gasto em criança chamadas.
TODO: porque é que main está ausente da saída {[[46]}, apesar de a poder ver num bt no GDB? função em falta na saída do GProf acho que é porque o gprof também é recolha de amostras com base em instrumentos compilados, e -O3 main é demasiado rápido e não tem amostras.
Eu escolho o resultado SVG em vez de PNG porque o SVG é pesquisável com Ctrl + F E o tamanho do ficheiro pode ser cerca de 10x menor. Além disso, a largura e altura da imagem gerada pode ser enorme com dezenas de milhares de pixels para software complexo, e GNOME eog 3.28.1 bugs para fora nesse caso para PNGs, enquanto SVGs são abertos pelo meu navegador automaticamente. gimp 2, 8 no entanto, funcionou bem, Ver também:
- https://askubuntu.com/questions/1112641/how-to-view-extremely-large-images
- https://unix.stackexchange.com/questions/77968/viewing-large-image-on-linux
- https://superuser.com/questions/356038/viewer-for-huge-images-under-linux-100-mp-color-images
Mas mesmo assim, você estará arrastando a imagem em torno de um monte para encontrar o que você quer, veja, por exemplo, esta imagem de um exemplo de software "real"retirado deste bilhete:

Você pode, no entanto, usar o mapa de cores para mitigar um pouco esses problemas. Por exemplo, na imagem anterior enorme, eu finalmente consegui encontrar o caminho crítico à esquerda quando fiz a brilhante dedução de que o verde vem depois do vermelho, seguido finalmente por azul mais escuro e mais escuro.
Em alternativa, também podemos observar a saída de texto da ferramenta binutils embutida gprof que salvámos anteriormente em:
cat main.gprof
Por omissão, isto produz uma saída extremamente descritiva que explica o que os dados de saída significam. Como não posso explicar melhor do que isso, deixo-te lê-lo tu mesmo.
Depois de ter compreendido o formato de saída de dados, poderá reduzir a verbosidade para mostrar apenas os dados sem o tutorial com a opção -b:
gprof -b main.out
-O0:
Flat profile:
Each sample counts as 0.01 seconds.
% cumulative self self total
time seconds seconds calls s/call s/call name
100.35 3.67 3.67 123003 0.00 0.00 common
0.00 3.67 0.00 3 0.00 0.03 fast
0.00 3.67 0.00 3 0.00 1.19 maybe_slow
Call graph
granularity: each sample hit covers 2 byte(s) for 0.27% of 3.67 seconds
index % time self children called name
0.09 0.00 3003/123003 fast [4]
3.58 0.00 120000/123003 maybe_slow [3]
[1] 100.0 3.67 0.00 123003 common [1]
-----------------------------------------------
<spontaneous>
[2] 100.0 0.00 3.67 main [2]
0.00 3.58 3/3 maybe_slow [3]
0.00 0.09 3/3 fast [4]
-----------------------------------------------
0.00 3.58 3/3 main [2]
[3] 97.6 0.00 3.58 3 maybe_slow [3]
3.58 0.00 120000/123003 common [1]
-----------------------------------------------
0.00 0.09 3/3 main [2]
[4] 2.4 0.00 0.09 3 fast [4]
0.09 0.00 3003/123003 common [1]
-----------------------------------------------
Index by function name
[1] common [4] fast [3] maybe_slow
E para -O3:
Flat profile:
Each sample counts as 0.01 seconds.
% cumulative self self total
time seconds seconds calls us/call us/call name
100.52 1.84 1.84 123003 14.96 14.96 common
Call graph
granularity: each sample hit covers 2 byte(s) for 0.54% of 1.84 seconds
index % time self children called name
0.04 0.00 3003/123003 fast [3]
1.79 0.00 120000/123003 maybe_slow [2]
[1] 100.0 1.84 0.00 123003 common [1]
-----------------------------------------------
<spontaneous>
[2] 97.6 0.00 1.79 maybe_slow [2]
1.79 0.00 120000/123003 common [1]
-----------------------------------------------
<spontaneous>
[3] 2.4 0.00 0.04 fast [3]
0.04 0.00 3003/123003 common [1]
-----------------------------------------------
Index by function name
[1] common
Como um resumo muito rápido para cada secção por exemplo:
0.00 3.58 3/3 main [2]
[3] 97.6 0.00 3.58 3 maybe_slow [3]
3.58 0.00 120000/123003 common [1]
Gira em torno da função que fica indentada (maybe_flow). [3] é o ID dessa função. Acima da função, estão seus chamadores, e abaixo dela os chamados.
Para -O3, veja aqui como na saída gráfica que maybe_slow e fast não têm um pai conhecido, que é o que a documentação diz que <spontaneous> significa.
Não tenho a certeza se existe uma boa maneira de fazer perfis linha-a-linha com o gprof: o tempo 'gprof' gasto em determinadas linhas de código
Valgrind callgrind
O Valgrind executa o programa através da máquina virtual valgrind. Isso torna o perfil muito preciso, mas também produz uma desaceleração Muito Grande do programa. Eu também mencionei kcachegrind anteriormente em: Ferramentas para obter um gráfico de chamada de função pictórica de códigoO Callgrind é a Ferramenta do valgrind para o código do perfil e o kcachegrind é um programa do KDE que pode visualizar o cachegrind saida.
Primeiro temos que remover a bandeira -pg para voltar à compilação normal, caso contrário a execução realmente falha com Profiling timer expired, e sim, isso é tão comum que eu fiz e havia uma questão de excesso de pilha para isso.
sudo apt install kcachegrind valgrind
gcc -ggdb3 -O3 -std=c99 -Wall -Wextra -pedantic -o main.out main.c
time valgrind --tool=callgrind valgrind --dump-instr=yes \
--collect-jumps=yes ./main.out 10000
I enable --dump-instr=yes --collect-jumps=yes because this also dumps information that enables us to view A per assembly line breakdown of performance, at a relatively small added overhead cost.
Fora de questão, time diz - nos que o programa levou 29,5 segundos para ser executado, por isso tivemos uma desaceleração de cerca de 15x neste exemplo. É evidente que este abrandamento vai constituir uma séria limitação para maiores cargas de trabalho. Sobre o " exemplo de software do mundo real "mencionado aqui , eu observei uma desaceleração de 80x.
A execução gera um ficheiro de dados de perfil chamado callgrind.out.<pid> por exemplo callgrind.out.8554 no meu caso. Nós vemos esse arquivo com:
kcachegrind callgrind.out.8554
Que mostra uma interface gráfica que contém dados semelhantes ao gprof textual resultado:

Além disso, se formos na página "Call Graph" da direita inferior, vemos um gráfico de chamadas que podemos exportar clicando com o botão direito para obter a seguinte imagem com quantidades irrazoáveis de contorno branco: -)

Eu acho que fast não está a aparecer nesse gráfico porque o kcachegrind deve ter simplificado a visualização porque essa chamada demora muito pouco tempo, provavelmente este será o comportamento que deseja num real programa. O menu do botão direito tem algumas configurações para controlar quando eliminar tais nós, mas eu não poderia obtê-lo para mostrar uma chamada tão curta após uma tentativa rápida. Se eu clicar em fast na janela esquerda, ele mostra um gráfico de chamadas com fast, de modo que essa pilha foi realmente capturada. Ainda ninguém tinha encontrado uma forma de mostrar o grafo completo de chamadas de grafos: Make callgrind show all function calls in the kcachegrind callgraph
TODO em software C++ complexo, vejo algumas entradas do tipo <cycle N>, por exemplo, onde eu esperaria nomes de funções, o que significa isso? Reparei que há um botão de "detecção de ciclo" para ligar e desligar isso, mas o que significa?
perf de linux-tools
perf parece usar exclusivamente mecanismos de amostragem de kernel Linux. Isso faz com que seja muito simples de configurar, mas também não totalmente preciso.
sudo apt install linux-tools
time perf record -g ./main.out 10000
Isto adicionou 0,2 s à execução, por isso, estamos bem em termos de tempo, mas ainda não vejo muito interesse, depois de expandir o common nó com a seta para a direita do teclado:
Samples: 7K of event 'cycles:uppp', Event count (approx.): 6228527608
Children Self Command Shared Object Symbol
- 99.98% 99.88% main.out main.out [.] common
common
0.11% 0.11% main.out [kernel] [k] 0xffffffff8a6009e7
0.01% 0.01% main.out [kernel] [k] 0xffffffff8a600158
0.01% 0.00% main.out [unknown] [k] 0x0000000000000040
0.01% 0.00% main.out ld-2.27.so [.] _dl_sysdep_start
0.01% 0.00% main.out ld-2.27.so [.] dl_main
0.01% 0.00% main.out ld-2.27.so [.] mprotect
0.01% 0.00% main.out ld-2.27.so [.] _dl_map_object
0.01% 0.00% main.out ld-2.27.so [.] _xstat
0.00% 0.00% main.out ld-2.27.so [.] __GI___tunables_init
0.00% 0.00% main.out [unknown] [.] 0x2f3d4f4944555453
0.00% 0.00% main.out [unknown] [.] 0x00007fff3cfc57ac
0.00% 0.00% main.out ld-2.27.so [.] _start
Então eu tento comparar o programa -O0 para ver se isso mostra alguma coisa, e só agora, finalmente, eu vejo um gráfico de chamadas:
Samples: 15K of event 'cycles:uppp', Event count (approx.): 12438962281
Children Self Command Shared Object Symbol
+ 99.99% 0.00% main.out [unknown] [.] 0x04be258d4c544155
+ 99.99% 0.00% main.out libc-2.27.so [.] __libc_start_main
- 99.99% 0.00% main.out main.out [.] main
- main
- 97.54% maybe_slow
common
- 2.45% fast
common
+ 99.96% 99.85% main.out main.out [.] common
+ 97.54% 0.03% main.out main.out [.] maybe_slow
+ 2.45% 0.00% main.out main.out [.] fast
0.11% 0.11% main.out [kernel] [k] 0xffffffff8a6009e7
0.00% 0.00% main.out [unknown] [k] 0x0000000000000040
0.00% 0.00% main.out ld-2.27.so [.] _dl_sysdep_start
0.00% 0.00% main.out ld-2.27.so [.] dl_main
0.00% 0.00% main.out ld-2.27.so [.] _dl_lookup_symbol_x
0.00% 0.00% main.out [kernel] [k] 0xffffffff8a600158
0.00% 0.00% main.out ld-2.27.so [.] mmap64
0.00% 0.00% main.out ld-2.27.so [.] _dl_map_object
0.00% 0.00% main.out ld-2.27.so [.] __GI___tunables_init
0.00% 0.00% main.out [unknown] [.] 0x552e53555f6e653d
0.00% 0.00% main.out [unknown] [.] 0x00007ffe1cf20fdb
0.00% 0.00% main.out ld-2.27.so [.] _start
maybe_slow e fast foram muito rápidos e não conseguiram nenhuma amostra? Funciona bem com -O3 em programas maiores que demoram mais tempo a executar? Perdi alguma opção CLI? Eu descobri sobre -F para controlar a frequência da amostra em Hertz, mas eu aumentei o máximo permitido por padrão de -F 39500 (pode ser aumentado com sudo) e ainda não vejo chamadas claras.
Uma coisa fixe sobre o FlameGraph é a ferramenta de Brendan Gregg que mostra os horários das pilhas de chamadas de uma forma muito limpa que lhe permite ver rapidamente as grandes chamadas. A ferramenta está disponível em: https://github.com/brendangregg/FlameGraph e também é mencionado no seu tutorial perf em: http://www.brendangregg.com/perf.html#FlameGraphs quando corri perf sem {[89] } consegui ERROR: No stack counts found por isso, por agora, vou fazê-lo com sudo:
git clone https://github.com/brendangregg/FlameGraph
sudo perf record -F 99 -g -o perf_with_stack.data ./main.out 10000
sudo perf script -i perf_with_stack.data | FlameGraph/stackcollapse-perf.pl | FlameGraph/flamegraph.pl > flamegraph.svg
Mas num programa tão simples, a saída não é muito fácil de entender, uma vez que não podemos ver facilmente nem maybe_slow nem fast nesse gráfico:

Num exemplo mais complexo torna-se claro o que o gráfico significa:

[unknown] nesse exemplo, por que isso?
Outra interface gráfica perf que pode valer a pena incluir:
-
Eclipse Trace Compass plugin: https://www.eclipse.org/tracecompass/
Mas isto tem a desvantagem de que você tem que primeiro converter os dados para o formato de traço comum, que pode ser feito com {[[98]}, mas precisa ser ativado no tempo de construção/ter
perfnovo o suficiente, qualquer um dos quais não é o caso para o perf no Ubuntu 18. 04 -
Https://github.com/KDAB/hotspot
A desvantagem disto é que parece não haver nenhum pacote Ubuntu, e a sua construção requer Qt 5.10 enquanto Ubuntu 18.04 está no Qt 5.9.
Gperftools
Anteriormente chamado de "ferramentas de desempenho do Google", fonte: https://github.com/gperftools/gperftools com base na amostra.
Primeiro instalar gperftools com:
sudo apt install google-perftools
Então, podemos ativar o compilador de CPU gperftools de duas maneiras: em tempo de execução, ou em tempo de construção.
Em tempo de execução, temos que passar conjunto a LD_PRELOAD para apontar para libprofiler.so, que você pode encontrar com locate libprofiler.so, por exemplo, no meu sistema:
gcc -ggdb3 -O3 -std=c99 -Wall -Wextra -pedantic -o main.out main.c
LD_PRELOAD=/usr/lib/x86_64-linux-gnu/libprofiler.so \
CPUPROFILE=prof.out ./main.out 10000
Em alternativa, podemos construir a biblioteca no tempo de ligação, dispensando a passagem LD_PRELOAD no tempo de execução:
gcc -Wl,--no-as-needed,-lprofiler,--as-needed -ggdb3 -O3 -std=c99 -Wall -Wextra -pedantic -o main.out main.c
CPUPROFILE=prof.out ./main.out 10000
Ver também: ficheiro gperftools-perfil não objecto de dumping
A melhor maneira de ver estes dados Descobri até agora que é fazer com que o resultado do pprof seja o mesmo formato que o kcachegrind toma como entrada (sim, a ferramenta Valgrind-project-viewer-tool) e usar o kcachegrind para ver que:
google-pprof --callgrind main.out prof.out > callgrind.out
kcachegrind callgrind.out
Depois de correr com qualquer um desses métodos, obtemos um ficheiro de dados de perfil como resultado. Podemos ver esse ficheiro graficamente como um SVG com:
google-pprof --web main.out prof.out

Que dá como um gráfico de chamadas familiar como outras ferramentas, mas com a unidade de número de amostras em vez de segundo.
Em alternativa, também podemos obter alguns dados textuais com:
google-pprof --text main.out prof.out
Que dá:
Using local file main.out.
Using local file prof.out.
Total: 187 samples
187 100.0% 100.0% 187 100.0% common
0 0.0% 100.0% 187 100.0% __libc_start_main
0 0.0% 100.0% 187 100.0% _start
0 0.0% 100.0% 4 2.1% fast
0 0.0% 100.0% 187 100.0% main
0 0.0% 100.0% 183 97.9% maybe_slow
Ver também: como utilizar as ferramentas do google perf
Programe o seu código com 'syscalls' raw perf_event_open
Eu acho que este é o mesmo subsistema subjacente que perf usa, mas é claro que você poderia atingir um controle ainda maior, instrumentando explicitamente o seu programa em tempo de compilação com eventos de interesse.
Testado no Ubuntu 18.04, gprof2dot 2019.11.30, valgrind 3.13.0, perf 4.15.18, Linux kernel 4.15.0, FLameGraph 1a0dc6985aad06e76857cf2a354bd5ba0c9ce96b, gperftools 2.5-2.
Para programas simples pode usar igprof , o Profiler ignominioso: https://igprof.org / .
É um analisador de amostras, de acordo com as linhas do... longo... resposta de Mike Dunlavey, que irá embrulhar os resultados em uma árvore de pilha de chamadas browsable, anotado com o tempo ou memória gasto em cada função, cumulativo ou por função.
Também vale a pena mencionar são
- HPCToolkit ( http://hpctoolkit.org/) - Open-source, funciona para programas paralelos e tem uma interface gráfica com a qual olhar para os resultados de várias formas Intel VTune ([9]} https://software.intel.com/en-us/vtune se tem compiladores de informações, isto é muito bom.
- TAU (http://www.cs.uoregon.edu/research/tau/home.php)
Usei HPCToolkit e VTune e são muito eficazes em encontrar o vara longa na Tenda e não precisa do seu código para ser recompilado (exceto que você tem que usar-g-o ou RelWithDebInfo tipo build em CMake para obter uma saída significativa). Ouvi dizer que TAU é semelhante em capacidades.
Estes são os dois métodos que uso para acelerar o meu código:
para aplicações ligadas ao CPU:
- utilize um profiler no modo de depuração para identificar partes questionáveis do seu código
- depois mude para o modo de lançamento e comente as secções questionáveis do seu código (assinale-o sem nada) até ver alterações no desempenho.
para pedidos encadernados:
- usar um profiler no modo de libertação para identifique partes questionáveis do seu código.
N. B.
Se não tens um profiler, usa o profiler do pobre homem. Carregue em pausa enquanto depila a sua aplicação. A maioria das suites do desenvolvedor vai entrar em conjunto com números de linha comentados. É estatisticamente provável que aterres numa região que está a consumir a maioria dos ciclos da CPU.Para O CPU, a razão para traçar perfis no modo de depuração é porque se o seu perfil tentado no modo de libertação, o compilador é vai reduzir a matemática, vetorizar loops, e funções inline que tende a globar seu código em uma bagunça não mapável quando é montado. uma confusão não mapável significa que o seu profiler não será capaz de identificar claramente o que está a demorar tanto porque a montagem pode não corresponder ao código fonte sob optimização. Se precisar do desempenho (por exemplo, sensível ao timing) do modo RELEASE, desactive as funcionalidades do depurador de acordo com as necessidades para manter um desempenho utilizável.
Para ligação I / O, o profiler ainda pode identificar operações de I/O no modo RELEASE porque as operações de I / O estão ligadas externamente a uma biblioteca partilhada (na maioria das vezes) ou, no pior dos casos, resultarão num vector de interrupção de chamada de sistemas (que também é facilmente identificável pelo profiler).
Pode usar uma estrutura de registo como loguru uma vez que inclui datas temporais e tempo de funcionamento total que podem ser utilizados de forma adequada para o perfil:

Pode usar a biblioteca iprof:
Https://gitlab.com/Neurochrom/iprof
Https://github.com/Neurochrom/iprof
É multi-plataforma e permite - lhe não medir o desempenho da sua aplicação também em tempo real. Você pode até juntá-lo com um gráfico ao vivo. Renúncia total: eu sou o autor.
Está em C++ e deve ser personalizado de acordo com as suas necessidades. Infelizmente não posso partilhar Códigos, apenas conceitos.
Você usa um buffer" grande " volatile contendo datas e ID do evento que você pode enviar post mortem ou depois de parar o sistema de registro (e despeje isso em um arquivo, por exemplo).
Recuperas o suposto buffer grande com todo o os dados e uma pequena interface analisam-na e mostram eventos com nome (up / down + value), como um osciloscópio faz com cores (configurado no ficheiro .hpp).
Precisas de 3 ficheiros:
toolname.hpp // interface
toolname.cpp // code
tool_events_id.hpp // Events ID
// EVENT_NAME ID BEGIN_END BG_COLOR NAME
#define SOCK_PDU_RECV_D 0x0301 //@D00301 BGEEAAAA # TX_PDU_Recv
#define SOCK_PDU_RECV_F 0x0302 //@F00301 BGEEAAAA # TX_PDU_Recv
Também define algumas funções em toolname.hpp :
#define LOG_LEVEL_ERROR 0
#define LOG_LEVEL_WARN 1
// ...
void init(void);
void probe(id,payload);
// etc
Onde quer que esteja no seu código, pode usar:
toolname<LOG_LEVEL>::log(EVENT_NAME,VALUE);
A função probe usa algumas linhas de montagem para recuperar a hora do relógio O MAIS RÁPIDO POSSÍVEL e, em seguida, define uma entrada no buffer. Nós também temos um incremento atômico para encontrar com segurança um índice onde armazenar o evento log.
Claro que o tampão é circular.
, na Verdade, um pouco surpreso, muitos não mencionou sobre google/benchmark , enquanto ele é um pouco pesado para fixar a área específica do código, especialmente se a base de código é um pouco grande, mas eu achei isso muito útil quando usado em combinação com callgrind
- o meu algoritmo está correcto ? Há fechaduras que provam ser pescoços de garrafa ? Há uma secção específica de código que está a provar ser um culpado ? Que tal IO, manipulado e optimizado ?
valgrind com a combinação de callrind e kcachegrind deve fornecer uma estimativa decente sobre os pontos acima e uma vez estabelecido que existem problemas com alguma secção de código, eu sugiro fazer uma marca de micro banco google benchmark é um bom lugar para começar.
Usar a opção -pg ao compilar e ligar o código e executar o ficheiro executável. Enquanto este programa é executado, os dados de análise são coletados no arquivo a. out.
Há dois tipos diferentes de perfis
1-perfil plano:
ao executar o comando gprog --flat-profile a.out você tem os seguintes dados
- qual a percentagem do tempo total gasto para a função,
-quantos segundos foram gastos numa função-incluindo e excluindo chamadas para sub-funções,
- o número de chamadas,
- o tempo médio por chamada.
2-análise gráfica
us o comando gprof --graph a.out para obter os seguintes dados para cada função que inclui
- Em cada secção, uma função é marcada com um número de índice.
- Acima da função, há uma lista de funções que chamam a função .
- Abaixo da função, há uma lista de funções que são chamadas pela função .
Usar um software de depuração como identificar onde o código está a correr lentamente ?
Basta pensar que você tem um obstáculo enquanto você está em movimento, então ele vai diminuir a sua velocidade
Assim como o looping indesejado da realocação, transbordos de buffer, busca, fugas de memória, etc, as operações consumem mais poder de execução que irá afectar negativamente o desempenho do Código., Certifique-se de adicionar-pg à compilação antes de traçar o perfil:g++ your_prg.cpp -pg ou {[1] } de acordo com o seu compilador
valgrind --tool=callgrind ./(Your binary)
Irá gerar um ficheiro chamado gmon.fora ou callgrind.as.X. poderá então usar a Ferramenta do kcachegrind ou depurador para ler este ficheiro. Ele lhe dará uma análise gráfica de coisas com resultados como quais linhas custam quanto.
Acho que sim.Como ninguém mencionou o mapa Arm, eu adicionei-o como pessoalmente usei o mapa com sucesso para traçar um programa científico C++.
Arm MAP é o profiler para códigos C, C++, Fortran e F90 paralelos, multithreaded ou simples threaded. Fornece uma análise aprofundada e um ponto de estrangulamento para a linha de origem. Ao contrário da maioria dos profilers, ele é projetado para ser capaz de perfil de pthreads, OpenMP ou MPI para código paralelo e roscado.
O mapa é um software comercial.