Como remover os valores anómalos de um conjunto de dados
8 answers
OK, devias aplicar uma coisa destas no teu conjunto de dados. Não substitua & gravar ou irá destruir os seus dados! E, btw, você (quase) nunca deve remover anómalos de seus dados:
remove_outliers <- function(x, na.rm = TRUE, ...) {
qnt <- quantile(x, probs=c(.25, .75), na.rm = na.rm, ...)
H <- 1.5 * IQR(x, na.rm = na.rm)
y <- x
y[x < (qnt[1] - H)] <- NA
y[x > (qnt[2] + H)] <- NA
y
}
Vê-lo em acção:
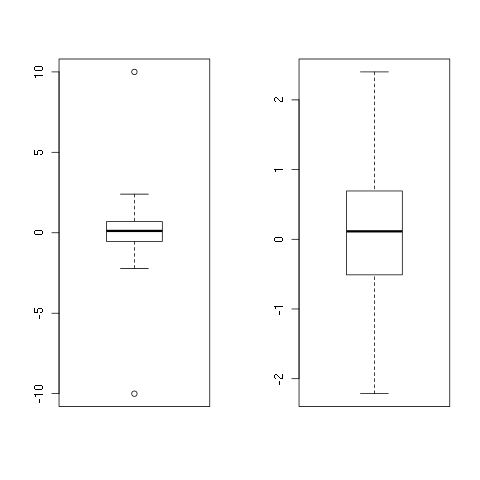
set.seed(1)
x <- rnorm(100)
x <- c(-10, x, 10)
y <- remove_outliers(x)
## png()
par(mfrow = c(1, 2))
boxplot(x)
boxplot(y)
## dev.off()
Editar: adicionei na.rm = TRUE por omissão.
EDIT2: removeu a função quantile, adicionando a subscrição, tornando assim a função mais rápida! =)
x[!x %in% boxplot.stats(x)$out]
Veja Também isto: http://www.r-statistics.com/2011/01/how-to-label-all-the-outliers-in-a-boxplot/
Utilize outline = FALSE como uma opção quando fizer o boxplot (leia a ajuda!).
> m <- c(rnorm(10),5,10)
> bp <- boxplot(m, outline = FALSE)
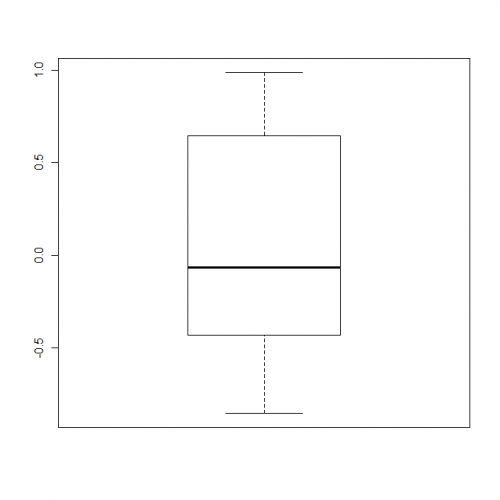
A função boxplot devolve os valores usados para fazer o desenho (que é feito de facto por bxp ():
bstats <- boxplot(count ~ spray, data = InsectSprays, col = "lightgray")
#need to "waste" this plot
bstats$out <- NULL
bstats$group <- NULL
bxp(bstats) # this will plot without any outlier points
x<-quantile(retentiondata$sum_dec_incr,c(0.01,0.99))
data_clean <- data[data$attribute >=x[1] & data$attribute<=x[2],]
Procurei pacotes relacionados com a remoção de valores anómalos, e encontrei este pacote (surpreendentemente chamado de "valores anómalos"!): https://cran.r-project.org/web/packages/outliers/outliers.pdf
se você passar por ele você vê diferentes maneiras de remover os anómalos e entre eles eu achei rm.outlier o mais conveniente para usar e como diz no link acima:
"Se o outlier é detectado e confirmado por testes estatísticos, esta função pode removê - lo ou substituí-lo por
média ou mediana da amostra " e também aqui está a parte de Utilização da mesma fonte:
"Utilização
rm.outlier(x, fill = FALSE, median = FALSE, opposite = FALSE)
Argumentos
x um conjunto de dados, mais frequentemente um vector. Se argumento é um dataframe, então outlier é
retirado de cada coluna por Safia. O mesmo comportamento é aplicado por aplicação
quando a matriz é dada.
preencher Se for verdadeiro, a mediana ou média é colocada em vez de ser mais estranha. Caso contrário, o
outlier(s) is/are simply removed.
mediana em vez de uma substituição estranha.
ao contrário, se configurado como verdadeiro, dá valor oposto (se o maior valor tiver a diferença máxima)
a partir da média, dá menor e vice-versa)
"
Adicionando à sugestão de @sefarkas e usando o quantile como cortes, pode-se explorar a seguinte opção:
newdata <- subset(mydata,!(mydata$var > quantile(mydata$var, probs=c(.01, .99))[2] | mydata$var < quantile(mydata$var, probs=c(.01, .99))[1]) )
Isto irá remover os pontos para além do 99º quantil. Deve ter-se cuidado como o que aL3Xa estava a dizer sobre a manutenção de valores anómalos. Deve ser removido apenas para obter uma visão conservadora alternativa dos dados.
Não faria:
z <- df[df$x > quantile(df$x, .25) - 1.5*IQR(df$x) &
df$x < quantile(df$x, .75) + 1.5*IQR(df$x), ] #rows