A gravar um ficheiro binário em C++ muito rapidamente
#include <fstream>
const unsigned long long size = 64ULL*1024ULL*1024ULL;
unsigned long long a[size];
int main()
{
std::fstream myfile;
myfile = std::fstream("file.binary", std::ios::out | std::ios::binary);
//Here would be some error handling
for(int i = 0; i < 32; ++i){
//Some calculations to fill a[]
myfile.write((char*)&a,size*sizeof(unsigned long long));
}
myfile.close();
}
compilado com Visual Studio 2010 e optimizações completas e executado sob janelas 7 este programa mapeia cerca de 20MB/S. O que realmente me incomoda é que o Windows pode copiar ficheiros de um outro SSD para este SSD em algum lugar entre 150MB/s e 200MB / S. assim, pelo menos 7 vezes mais rápido. Isso é ... porque acho que devia ser capaz de ir mais depressa.
Alguma ideia de Como posso acelerar a minha escrita?Edit: Agora compila.
12 answers
Isto fez o trabalho:
#include <stdio.h>
const unsigned long long size = 8ULL*1024ULL*1024ULL;
unsigned long long a[size];
int main()
{
FILE* pFile;
pFile = fopen("file.binary", "wb");
for (unsigned long long j = 0; j < 1024; ++j){
//Some calculations to fill a[]
fwrite(a, 1, size*sizeof(unsigned long long), pFile);
}
fclose(pFile);
return 0;
}
Acabei de cronometrar 8GB em 36sec, que é cerca de 220MB/s e acho que isso mapeia o meu SSD. Também vale a pena notar que o código na questão usou um núcleo 100%, enquanto este código usa apenas 2-5%.
Muito obrigado a todos.Update : 5 anos se passaram. Compiladores, hardware, bibliotecas e meus requisitos mudaram. Foi por isso que fiz algumas alterações ao código e fiz algumas medições.
Em primeiro lugar, Código:
#include <fstream>
#include <chrono>
#include <vector>
#include <cstdint>
#include <numeric>
#include <random>
#include <algorithm>
#include <iostream>
#include <cassert>
std::vector<uint64_t> GenerateData(std::size_t bytes)
{
assert(bytes % sizeof(uint64_t) == 0);
std::vector<uint64_t> data(bytes / sizeof(uint64_t));
std::iota(data.begin(), data.end(), 0);
std::shuffle(data.begin(), data.end(), std::mt19937{ std::random_device{}() });
return data;
}
long long option_1(std::size_t bytes)
{
std::vector<uint64_t> data = GenerateData(bytes);
auto startTime = std::chrono::high_resolution_clock::now();
auto myfile = std::fstream("file.binary", std::ios::out | std::ios::binary);
myfile.write((char*)&data[0], bytes);
myfile.close();
auto endTime = std::chrono::high_resolution_clock::now();
return std::chrono::duration_cast<std::chrono::milliseconds>(endTime - startTime).count();
}
long long option_2(std::size_t bytes)
{
std::vector<uint64_t> data = GenerateData(bytes);
auto startTime = std::chrono::high_resolution_clock::now();
FILE* file = fopen("file.binary", "wb");
fwrite(&data[0], 1, bytes, file);
fclose(file);
auto endTime = std::chrono::high_resolution_clock::now();
return std::chrono::duration_cast<std::chrono::milliseconds>(endTime - startTime).count();
}
long long option_3(std::size_t bytes)
{
std::vector<uint64_t> data = GenerateData(bytes);
std::ios_base::sync_with_stdio(false);
auto startTime = std::chrono::high_resolution_clock::now();
auto myfile = std::fstream("file.binary", std::ios::out | std::ios::binary);
myfile.write((char*)&data[0], bytes);
myfile.close();
auto endTime = std::chrono::high_resolution_clock::now();
return std::chrono::duration_cast<std::chrono::milliseconds>(endTime - startTime).count();
}
int main()
{
const std::size_t kB = 1024;
const std::size_t MB = 1024 * kB;
const std::size_t GB = 1024 * MB;
for (std::size_t size = 1 * MB; size <= 4 * GB; size *= 2) std::cout << "option1, " << size / MB << "MB: " << option_1(size) << "ms" << std::endl;
for (std::size_t size = 1 * MB; size <= 4 * GB; size *= 2) std::cout << "option2, " << size / MB << "MB: " << option_2(size) << "ms" << std::endl;
for (std::size_t size = 1 * MB; size <= 4 * GB; size *= 2) std::cout << "option3, " << size / MB << "MB: " << option_3(size) << "ms" << std::endl;
return 0;
}
Agora o código compila com Visual Studio 2017 e g++ 7.2.0 (que é agora um dos meus requisitos). Deixei o código funcionar com duas configurações:
- Laptop, Core i7, SSD, Ubuntu 16.04, g++ Version 7.2.0 com-std=c++11-march=native-O3
- Desktop, Core i7, SSD, Windows 10, Visual Studio 2017 Version 15.3.1 com /Ox / Ob2 / Oi / Ot /GT /GL / Gy
Que deu as seguintes medições (depois de se terem livrado dos valores de 1MB, porque eram óbvias casos anómalos):
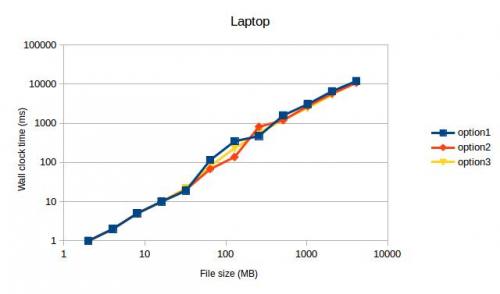
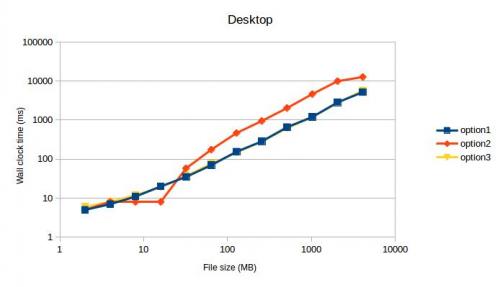 Ambas as vezes option1 e option3 max fora meu SSD. Não esperava que isto visse, porque o option2 era o código mais rápido da minha máquina naquela altura.
Ambas as vezes option1 e option3 max fora meu SSD. Não esperava que isto visse, porque o option2 era o código mais rápido da minha máquina naquela altura.
TL; DR : As minhas medições indicam utilizar std::fstream em FILE.
Tente o seguinte, por ordem:
-
Tamanho de tampão menor. Escrever ~2 MiB de cada vez pode ser um bom começo. No meu último portátil, ~512 KiB era o ponto doce, mas eu ainda não testei no meu SSD.
Nota: notei que buffers muito grandes tendem a diminuir o desempenho. Já reparei em perdas de velocidade com buffers de 16 MiB em vez de buffers de 512 KiB antes.
Use
_open(ou_topenSe quiser ser Windows-correct) para abrir o arquivo, então use_write. Isto irá provavelmente evitar muitos choques, mas não é certo.Usando funções específicas do Windows como
CreateFileeWriteFile. Isso evitará qualquer buffering na biblioteca padrão.
Não vejo diferença entre std:: stream/FILE / device. Entre buffering e non buffering.
Nota:
- as unidades de SSD "tendem" a abrandar (taxas de transferência mais baixas) à medida que se enchem.
- as unidades de SSD "tendem" a abrandar (taxas de transferência mais baixas) à medida que envelhecem (por não funcionarem bits).
Assim, uma taxa de transferência de: 260M / s (o meu SSD parece um pouco mais rápido do que o seu).
64 * 1024 * 1024 * 8 /*sizeof(unsigned long long) */ * 32 /*Chunks*/
= 16G
= 16G/63 = 260M/s
Obter um não aumento, movendo-se para o arquivo* de std::fstream.
#include <stdio.h>
using namespace std;
int main()
{
FILE* stream = fopen("binary", "w");
for(int loop=0;loop < 32;++loop)
{
fwrite(a, sizeof(unsigned long long), size, stream);
}
fclose(stream);
}
Então o fluxo de C++ está a funcionar o mais rápido que a biblioteca subjacente permitir.
Mas acho injusto comparar o SO a uma aplicação construída em cima do so. A aplicação não pode fazer suposições (ele não sabe que as unidades são SSD) e, portanto, usa os mecanismos de arquivo do SO para transferência.Embora o SO não precise de fazer suposições. Ele pode dizer os tipos de unidades envolvidas e usar a técnica ideal para transferir os dados. Neste caso, uma memória direta para a transferência de memória. Tente escrever um programa que copia 80G de um local na memória para outro e veja quão rápido isso é.
Editar
Mudei o meu código para usar as chamadas de nível inferior:
nada de buffering.
#include <fcntl.h>
#include <unistd.h>
const unsigned long long size = 64ULL*1024ULL*1024ULL;
unsigned long long a[size];
int main()
{
int data = open("test", O_WRONLY | O_CREAT, 0777);
for(int loop = 0; loop < 32; ++loop)
{
write(data, a, size * sizeof(unsigned long long));
}
close(data);
}
nota: A Minha unidade é uma unidade SSD se você tem uma unidade normal você pode ver uma diferença entre as duas técnicas acima. Mas como eu esperava não buffering e buffering (quando pedaços grandes de torção maior que o tamanho do buffer) não fazem diferença.
Editar 2:
Já tentou o método mais rápido de copiar ficheiros em C++
int main()
{
std::ifstream input("input");
std::ofstream output("ouptut");
output << input.rdbuf();
}
A melhor solução é implementar uma escrita async com buffering duplo.
Olha para a linha do tempo:
------------------------------------------------>
FF|WWWWWWWW|FF|WWWWWWWW|FF|WWWWWWWW|FF|WWWWWWWW|
O ' F 'representa o tempo de enchimento do buffer, e o' W ' representa o tempo de escrita do buffer no disco. Então o problema em perder tempo entre escrever buffers para arquivo. No entanto, ao implementar a escrita em um tópico separado, você pode começar a preencher o próximo buffer imediatamente assim:
------------------------------------------------> (main thread, fills buffers)
FF|ff______|FF______|ff______|________|
------------------------------------------------> (writer thread)
|WWWWWWWW|wwwwwwww|WWWWWWWW|wwwwwwww|
F - enchimento 1st buffer
f-enchimento do 2º tampão
W - a gravar o primeiro buffer no ficheiro
w-a gravar o 2º buffer no ficheiro
_ - espere enquanto a operação está concluída
Esta abordagem com swaps de buffer é muito útil quando o enchimento de um buffer requer computação mais complexa (daí, mais tempo). Eu sempre implemento uma classe CSequentialStreamWriter que esconde escrita assíncrona dentro, de modo que para o usuário final a interface tem apenas Função de Escrita.
E o tamanho do buffer deve ser um múltiplo do tamanho do conjunto de discos. Caso contrário, vais acabar com fraco desempenho, escrevendo um único buffer para 2 conjuntos de discos adjacentes.
A escrever o último buffer.Quando você chamar a função de escrita pela última vez, você tem que se certificar de que o buffer atual está sendo preenchido deve ser escrito no disco também. Assim, CSequentialStreamWriter deve ter um método separado, digamos Finalize( final buffer flush), que deve escrever em disco a última porção de dados.
Tratamento de erros.
Enquanto o código começa a preencher o segundo buffer, e o primeiro está sendo escrito em um fio separado, mas a escrita falha por alguma razão, o fio principal deve estar ciente dessa falha.
------------------------------------------------> (main thread, fills buffers)
FF|fX|
------------------------------------------------> (writer thread)
__|X|
Vamos supor que a interface de um CSequentialStreamWriter tem de Escrever a função retorna bool ou lança uma exceção, tendo, portanto, um erro em uma thread separada, você tem que lembrar que o estado, por isso, da próxima vez que você chamar de Gravação ou Finilize no thread principal, o método irá retornar False ou irá lançar uma exceção. E não importa em que ponto você parou de preencher um buffer, mesmo se você escreveu alguns dados à frente após a falha-o mais provável é que o arquivo seria corrompido e inútil.
Podias usar {[[2]} em vez disso, e medir o desempenho que ganhaste?
Um par de opções é usar fwrite/write em vez de fstream:
#include <stdio.h>
int main ()
{
FILE * pFile;
char buffer[] = { 'x' , 'y' , 'z' };
pFile = fopen ( "myfile.bin" , "w+b" );
fwrite (buffer , 1 , sizeof(buffer) , pFile );
fclose (pFile);
return 0;
}
Se decidir utilizar write, tente algo semelhante:
#include <unistd.h>
#include <fcntl.h>
int main(void)
{
int filedesc = open("testfile.txt", O_WRONLY | O_APPEND);
if (filedesc < 0) {
return -1;
}
if (write(filedesc, "This will be output to testfile.txt\n", 36) != 36) {
write(2, "There was an error writing to testfile.txt\n", 43);
return -1;
}
return 0;
}
Também te aconselharia a investigar memory map. Essa pode ser a tua resposta. Uma vez eu tive que processar um arquivo 20GB em outro para armazená-lo no banco de dados, e o arquivo como nem mesmo abrir. Então, a solução para utilizar o mapa de moemory. Mas fiz isso em ...
Tente usar as chamadas da API open()/write()/close() e experimente o tamanho do buffer de saída. Quero dizer não passar todo o buffer "muitos-muitos-bytes" de uma vez, fazer um par de escritas (ou seja, TotalNumBytes / OutBufferSize). OutBufferSize pode ser de 4096 bytes a megabyte.
Outra tentativa de uso WinAPI OpenFile/CreateFile e usar este artigo do MSDN para desactivar a memória intermédia (FILE_FLAG_NO_BUFFERING). E este artigo MSDN sobre o ficheiro de Escrita() mostra como obter o tamanho do bloco para a unidade para saber o tamanho de buffer ideal.
De qualquer forma, o ofstream é um invólucro e pode haver bloqueio nas operações de E/S. Tenha em mente que atravessar toda a matriz n-gigabyte também leva algum tempo. Enquanto você está escrevendo um buffer pequeno, ele chega ao cache e funciona mais rápido.Tente usar arquivos mapeados pela memória.
Se copiar algo do disco A para o disco B no explorer, o Windows utiliza o DMA. Isso significa que para a maioria do processo de cópia, a CPU basicamente não vai fazer nada além de dizer ao controlador de disco onde colocar, e obter dados, eliminando um passo inteiro na cadeia, e um que não é de todo otimizado para mover grandes quantidades de dados - e eu quero dizer hardware.
O que fazes envolve muito a CPU. Eu quero apontar para você a parte" alguns cálculos para preencher uma []". Que Eu pensar é essencial. Você gera um [], então você copia de um [] para um buffer de saída (isso é o que o fstream::write faz), então você gera novamente, etc.
O que fazer? Multithreading! (Eu espero que você tenha um processador multi-core)- Garfo.
- usar um tópico para gerar um [] Dados
- usar o outro para escrever dados de um [] para o disco
- vais precisar de duas matrizes a1 [] e a2 [] e trocar entre elas
- você vai precisar de algum tipo de sincronização entre o seu tópicos (semáforos, fila de mensagens, etc.)
- usar funções de nível inferior, não Barradas, como a funçãoWriteFile mencionada por Mehrdad
fstreamOs s não são mais lentos que os fluxos de C, por si só, mas usam mais CPU (especialmente se o 'buffering' não estiver devidamente configurado). Quando uma UCP satura, limita a taxa de E / S.
Pelo menos as cópias de implementação do MSVC 2015 1 char de cada vez para o buffer de saída quando um buffer de fluxo não está definido (ver streambuf::xsputn). Então certifique-se de definir um buffer de fluxo(>0).
Consigo obter uma velocidade de escrita de 1500MB / s (a velocidade máxima do meu SSD M. 2) com fstream usando isto código:
#include <iostream>
#include <fstream>
#include <chrono>
#include <memory>
#include <stdio.h>
#ifdef __linux__
#include <unistd.h>
#endif
using namespace std;
using namespace std::chrono;
const size_t sz = 512 * 1024 * 1024;
const int numiter = 20;
const size_t bufsize = 1024 * 1024;
int main(int argc, char**argv)
{
unique_ptr<char[]> data(new char[sz]);
unique_ptr<char[]> buf(new char[bufsize]);
for (size_t p = 0; p < sz; p += 16) {
memcpy(&data[p], "BINARY.DATA.....", 16);
}
unlink("file.binary");
int64_t total = 0;
if (argc < 2 || strcmp(argv[1], "fopen") != 0) {
cout << "fstream mode\n";
ofstream myfile("file.binary", ios::out | ios::binary);
if (!myfile) {
cerr << "open failed\n"; return 1;
}
myfile.rdbuf()->pubsetbuf(buf.get(), bufsize); // IMPORTANT
for (int i = 0; i < numiter; ++i) {
auto tm1 = high_resolution_clock::now();
myfile.write(data.get(), sz);
if (!myfile)
cerr << "write failed\n";
auto tm = (duration_cast<milliseconds>(high_resolution_clock::now() - tm1).count());
cout << tm << " ms\n";
total += tm;
}
myfile.close();
}
else {
cout << "fopen mode\n";
FILE* pFile = fopen("file.binary", "wb");
if (!pFile) {
cerr << "open failed\n"; return 1;
}
setvbuf(pFile, buf.get(), _IOFBF, bufsize); // NOT important
auto tm1 = high_resolution_clock::now();
for (int i = 0; i < numiter; ++i) {
auto tm1 = high_resolution_clock::now();
if (fwrite(data.get(), sz, 1, pFile) != 1)
cerr << "write failed\n";
auto tm = (duration_cast<milliseconds>(high_resolution_clock::now() - tm1).count());
cout << tm << " ms\n";
total += tm;
}
fclose(pFile);
auto tm2 = high_resolution_clock::now();
}
cout << "Total: " << total << " ms, " << (sz*numiter * 1000 / (1024.0 * 1024 * total)) << " MB/s\n";
}
Eu tentei este código em outras plataformas (Ubuntu, FreeBSD) e notei diferenças de taxa de I/O, mas uma Uso de CPU diferença de cerca de 8:1 (fstream usado 8 vezes mais CPU). Então pode-se imaginar, se eu tivesse um disco mais rápido, a escrita fstream iria abrandar mais cedo do que a versão stdio.
Se quiser escrever depressa para os fluxos de ficheiros, então poderá tornar o 'stream' do buffer de leitura maior:
wfstream f;
const size_t nBufferSize = 16184;
wchar_t buffer[nBufferSize];
f.rdbuf()->pubsetbuf(buffer, nBufferSize);
Também, ao escrever muitos dados para arquivos é às vezes mais rápido para logicamente estender o tamanho do arquivo em vez de fisicamente, isso é porque, ao estender logicamente um arquivo o sistema de arquivos não zero o novo espaço para fora antes de escrever para ele. Também é inteligente para logicamente estender o arquivo mais do que você realmente precisa para evitar lotes de extensões de arquivo. Ficheiro lógico a extensão é suportada no Windows, invocando SetFileValidData ou xfsctl com XFS_IOC_RESVSP64 nos sistemas XFS.
Im compilar o meu programa no gcc em GNU/Linux e mingw no win 7 e win xp e funcionou de boa
Você pode usar o meu programa e para criar um arquivo de 80 GB basta mudar a linha 33 para
makeFile("Text.txt",1024,8192000);
Quando sair do programa, o ficheiro será destruído e, em seguida, verifique o ficheiro quando estiver a correr
Ter o programa que você quer apenas mudar o programa
Firt one é o programa windows e o segundo é para GNU / Linux