Gerar um mapa de Heat no MatPlotLib usando um conjunto de dados de dispersão
Eu tenho um conjunto de pontos de dados X,Y (cerca de 10k) que são fáceis de traçar como um gráfico de dispersão, mas que eu gostaria de representar como um mapa de calor.
Eu vi os exemplos em MatPlotLib e todos eles parecem já começar com valores de células heatmap para gerar a imagem.
Existe um método que converte um monte de x,y, todos diferentes, para um mapa de calor (onde zonas com maior frequência de x,y seriam "mais quentes")?
8 answers
Se não queres hexágonos, podes usar a função de numpy histogram2d:
import numpy as np
import numpy.random
import matplotlib.pyplot as plt
# Generate some test data
x = np.random.randn(8873)
y = np.random.randn(8873)
heatmap, xedges, yedges = np.histogram2d(x, y, bins=50)
extent = [xedges[0], xedges[-1], yedges[0], yedges[-1]]
plt.clf()
plt.imshow(heatmap.T, extent=extent, origin='lower')
plt.show()
bins=(512, 384) Na chamada para histogram2d.
Exemplo: 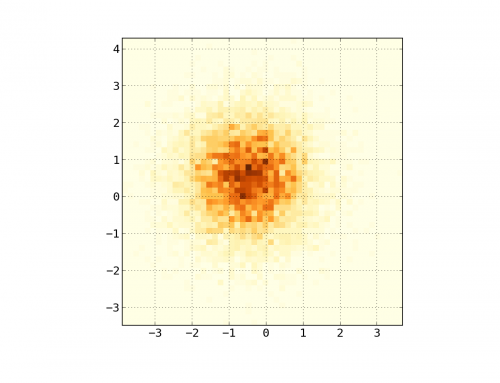
EmMatplotlib léxico, acho que queres umhexbin enredo.
Se você não está familiarizado com este tipo de enredo, é apenas um histograma bivariato {[[4]} em que o plano xy é tesselado por uma grade regular de hexágonos.
Então, a partir de um histograma, você pode apenas contar o número de pontos que caem em cada hexágono, discretizar a região de desenho como um conjunto de janelas, atribuir cada ponto a uma destas janelas; finalmente, mapear as janelas num Matriz de cores , e você tem um diagrama de hexbin.
Embora menos comummente usado do que por exemplo, círculos, ou quadrados, que hexágonos são uma melhor escolha para a geometria do recipiente binning é intuitiva:
Hexágonos têm simetria vizinha mais próxima (por exemplo, os caixotes não têm, por exemplo, a distância de um ponto na fronteira de um quadrado a um ponto dentro desse quadrado não é em toda parte igual) e
Hexágono é o mais alto n-polígono que dá plano regular tessellation (Isto é, pode remodelar o chão da sua cozinha de forma hexagonal porque não terá espaço vazio entre os azulejos quando terminar--não é verdade para todos os outros mais altos-n, n >= 7, polígonos).
(Matplotlib usa o termo hexbin enredo; para fazer (AFAIK) todos os plotagem de bibliotecas para R; ainda não sei se isso é geralmente aceites prazo para as parcelas deste tipo, embora eu suspeite que é provável dado que hexbin é o diminutivo de binning hexagonal , que descreve o passo essencial na preparação dos dados para visualização.)
from matplotlib import pyplot as PLT
from matplotlib import cm as CM
from matplotlib import mlab as ML
import numpy as NP
n = 1e5
x = y = NP.linspace(-5, 5, 100)
X, Y = NP.meshgrid(x, y)
Z1 = ML.bivariate_normal(X, Y, 2, 2, 0, 0)
Z2 = ML.bivariate_normal(X, Y, 4, 1, 1, 1)
ZD = Z2 - Z1
x = X.ravel()
y = Y.ravel()
z = ZD.ravel()
gridsize=30
PLT.subplot(111)
# if 'bins=None', then color of each hexagon corresponds directly to its count
# 'C' is optional--it maps values to x-y coordinates; if 'C' is None (default) then
# the result is a pure 2D histogram
PLT.hexbin(x, y, C=z, gridsize=gridsize, cmap=CM.jet, bins=None)
PLT.axis([x.min(), x.max(), y.min(), y.max()])
cb = PLT.colorbar()
cb.set_label('mean value')
PLT.show()
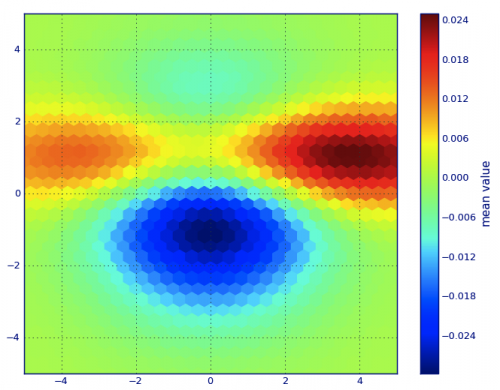
Em vez de usar np.o hist2d, que em geral produz histogramas bastante feios, gostaria de reciclar py-sphviewer, um pacote python para representar simulações de partículas usando um kernel de suavização adaptativo e que pode ser facilmente instalado a partir do pip (ver documentação da página web). Considere o seguinte código, que é baseado no exemplo:
import numpy as np
import numpy.random
import matplotlib.pyplot as plt
import sphviewer as sph
def myplot(x, y, nb=32, xsize=500, ysize=500):
xmin = np.min(x)
xmax = np.max(x)
ymin = np.min(y)
ymax = np.max(y)
x0 = (xmin+xmax)/2.
y0 = (ymin+ymax)/2.
pos = np.zeros([3, len(x)])
pos[0,:] = x
pos[1,:] = y
w = np.ones(len(x))
P = sph.Particles(pos, w, nb=nb)
S = sph.Scene(P)
S.update_camera(r='infinity', x=x0, y=y0, z=0,
xsize=xsize, ysize=ysize)
R = sph.Render(S)
R.set_logscale()
img = R.get_image()
extent = R.get_extent()
for i, j in zip(xrange(4), [x0,x0,y0,y0]):
extent[i] += j
print extent
return img, extent
fig = plt.figure(1, figsize=(10,10))
ax1 = fig.add_subplot(221)
ax2 = fig.add_subplot(222)
ax3 = fig.add_subplot(223)
ax4 = fig.add_subplot(224)
# Generate some test data
x = np.random.randn(1000)
y = np.random.randn(1000)
#Plotting a regular scatter plot
ax1.plot(x,y,'k.', markersize=5)
ax1.set_xlim(-3,3)
ax1.set_ylim(-3,3)
heatmap_16, extent_16 = myplot(x,y, nb=16)
heatmap_32, extent_32 = myplot(x,y, nb=32)
heatmap_64, extent_64 = myplot(x,y, nb=64)
ax2.imshow(heatmap_16, extent=extent_16, origin='lower', aspect='auto')
ax2.set_title("Smoothing over 16 neighbors")
ax3.imshow(heatmap_32, extent=extent_32, origin='lower', aspect='auto')
ax3.set_title("Smoothing over 32 neighbors")
#Make the heatmap using a smoothing over 64 neighbors
ax4.imshow(heatmap_64, extent=extent_64, origin='lower', aspect='auto')
ax4.set_title("Smoothing over 64 neighbors")
plt.show()
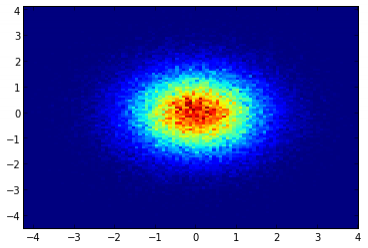
Que produz a seguinte imagem:

A função myplot é apenas uma função muito simples que eu escrevi em ordem para dar os dados x, y ao py-sphviewer para fazer a magia.
Se estiver a utilizar 1, 2.x
x = randn(100000) y = randn(100000) hist2d(x,y,bins=100);
Sei que esta é uma pergunta antiga, mas queria adicionar algo ao anwser do Alejandro: se quiser uma imagem suavizada sem usar o py-sphviewer, poderá usar np.histogram2d e aplicar um filtro gaussiano (de scipy.ndimage.filters) ao mapa de calor:
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.cm as cm
from scipy.ndimage.filters import gaussian_filter
def myplot(x, y, s, bins=1000):
heatmap, xedges, yedges = np.histogram2d(x, y, bins=bins)
heatmap = gaussian_filter(heatmap, sigma=s)
extent = [xedges[0], xedges[-1], yedges[0], yedges[-1]]
return heatmap.T, extent
fig, axs = plt.subplots(2, 2)
# Generate some test data
x = np.random.randn(1000)
y = np.random.randn(1000)
sigmas = [0, 16, 32, 64]
for ax, s in zip(axs.flatten(), sigmas):
if s == 0:
ax.plot(x, y, 'k.', markersize=5)
ax.set_title("Scatter plot")
else:
img, extent = myplot(x, y, s)
ax.imshow(img, extent=extent, origin='lower', cmap=cm.jet)
ax.set_title("Smoothing with $\sigma$ = %d" % s)
plt.show()
Produz:

O enredo de dispersão E s = 16 plotados em cima de eachother para Agape Gal'lo (clique para melhor ver):

Uma diferença que notei com a minha abordagem gaussiana do filtro e com a abordagem do Alejandro foi que o método dele mostra estruturas locais muito melhores do que as minhas. Por isso, implementei um método vizinho mais simples a nível de pixels. Este método calcula para cada pixel a soma inversa das distâncias dos pontos mais próximos dos dados
n. Este método é em alta resolução muito caro computacionalmente e eu acho que há uma maneira mais rápida, então avisa-me se tiveres alguma melhoria. De qualquer forma, aqui está o código:
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.cm as cm
def data_coord2view_coord(p, vlen, pmin, pmax):
dp = pmax - pmin
dv = (p - pmin) / dp * vlen
return dv
def nearest_neighbours(xs, ys, reso, n_neighbours):
im = np.zeros([reso, reso])
extent = [np.min(xs), np.max(xs), np.min(ys), np.max(ys)]
xv = data_coord2view_coord(xs, reso, extent[0], extent[1])
yv = data_coord2view_coord(ys, reso, extent[2], extent[3])
for x in range(reso):
for y in range(reso):
xp = (xv - x)
yp = (yv - y)
d = np.sqrt(xp**2 + yp**2)
im[y][x] = 1 / np.sum(d[np.argpartition(d.ravel(), n_neighbours)[:n_neighbours]])
return im, extent
n = 1000
xs = np.random.randn(n)
ys = np.random.randn(n)
resolution = 250
fig, axes = plt.subplots(2, 2)
for ax, neighbours in zip(axes.flatten(), [0, 16, 32, 64]):
if neighbours == 0:
ax.plot(xs, ys, 'k.', markersize=2)
ax.set_aspect('equal')
ax.set_title("Scatter Plot")
else:
im, extent = nearest_neighbours(xs, ys, resolution, neighbours)
ax.imshow(im, origin='lower', extent=extent, cmap=cm.jet)
ax.set_title("Smoothing over %d neighbours" % neighbours)
ax.set_xlim(extent[0], extent[1])
ax.set_ylim(extent[2], extent[3])
plt.show()
Resultado:

Seaborn agora tem a função jointplot que deve funcionar bem aqui:
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
# Generate some test data
x = np.random.randn(8873)
y = np.random.randn(8873)
sns.jointplot(x=x, y=y, kind='hex')
plt.show()

Faça uma matriz bidimensional que corresponda às células da sua imagem final, chamada say heatmap_cells e instancie - a como todos os zeros.
Escolha dois factores de escala que definem a diferença entre cada elemento array em unidades reais, para cada dimensão, digamos x_scale e y_scale. Escolha Estes de modo que todos os seus pontos de dados cairão dentro dos limites do array heatmap.
Para cada ponto de dados em bruto com x_value e y_value:
heatmap_cells[floor(x_value/x_scale),floor(y_value/y_scale)]+=1
x = data_x # between -10 and 4, log-gamma of an svc
y = data_y # between -4 and 11, log-C of an svc
z = data_z #between 0 and 0.78, f1-values from a difficult dataset
from matplotlib import pyplot as plt
from matplotlib import cm
import numpy as np
from scipy.interpolate import griddata
O último é importante especialmente porque a frequência dos pontos xy não é igualmente distribuída nos meus dados. Primeiro, vamos começar com alguns limites que se encaixam aos meus dados e um tamanho arbitrário da grade. Os dados originais também têm pontos de dados fora dos limites x e Y.
#determine grid boundaries
gridsize = 500
x_min = -8
x_max = 2.5
y_min = -2
y_max = 7
Nos meus dados, há muito mais do que os 500 valores disponíveis na área de alto interesse; enquanto na área de baixo interesse, não há sequer 200 valores na grelha total; entre os limites gráficos de x_min e x_max há ainda menos.
xx = np.linspace(x_min, x_max, gridsize) # array of x values
yy = np.linspace(y_min, y_max, gridsize) # array of y values
grid = np.array(np.meshgrid(xx, yy.T))
grid = grid.reshape(2, grid.shape[1]*grid.shape[2]).T
O Griddata calcula um valor por ponto na grelha, por um método predefinido. Eu escolho" mais próximo " - os pontos vazios da grelha serão preenchidos com valores do vizinho mais próximo. Isto parece que as áreas com menos informação têm células maiores (mesmo que não seja o caso). Um poderia optar por interpolar "linear", então as áreas com menos informação parecem menos afiadas. É uma questão de gosto.
points = np.array([x, y]).T # because griddata wants it that way
z_grid2 = griddata(points, z, grid, method='nearest')
# you get a 1D vector as result. Reshape to picture format!
z_grid2 = z_grid2.reshape(xx.shape[0], yy.shape[0])
E hop, entregamos ao matplotlib para mostrar o enredo
fig = plt.figure(1, figsize=(10, 10))
ax1 = fig.add_subplot(111)
ax1.imshow(z_grid2, extent=[x_min, x_max,y_min, y_max, ],
origin='lower', cmap=cm.magma)
ax1.set_title("SVC: empty spots filled by nearest neighbours")
ax1.set_xlabel('log gamma')
ax1.set_ylabel('log C')
plt.show()
