Uma explicação simples do MapReduce?
relacionado com a minha perguntaCouchDB .
Alguém pode explicar o MapReduce em termos que um idiota pode entender?8 answers
Indo até o básico para o mapa e reduzir.
Mapa é uma função que "transforma" itens em algum tipo de lista para outro tipo de item e colocá-los de volta no mesmo tipo de lista.
Suponha que eu tenho uma lista de números: [1,2,3] e eu quero dobrar cada número, neste caso, a função para "dobrar cada número" é a função x = x * 2. E sem mapeamentos, eu poderia escrever um simples loop, digamos
A = [1, 2, 3]
foreach (item in A) A[item] = A[item] * 2
E eu teria A = [2, 4, 6] mas em vez de escrever loops, se eu tenho uma função de mapa eu poderia escrever
A = [1, 2, 3].Map(x => x * 2)
O x = > x * 2 é uma função a ser executada contra os elementos em [1,2,3]. O que acontece é que o programa pega cada item, executa (x => x * 2) contra ele, fazendo x igual para cada item, e produz uma lista dos resultados.
1 : 1 => 1 * 2 : 2
2 : 2 => 2 * 2 : 4
3 : 3 => 3 * 2 : 6
Assim, depois de executar a função do mapa com (x = > x * 2) Você teria [2, 4, 6].
Reduzir é uma função que "recolhe" os itens em lista e executa alguns cálculos em todos deles, reduzindo-os assim a um único valor.
Encontrar uma soma ou encontrar médias são todas as instâncias de uma função de redução. Como se você tivesse uma lista de números, digamos [7, 8, 9] e os quisesse resumidos, você escreveria um loop como este
A = [7, 8, 9]
sum = 0
foreach (item in A) sum = sum + A[item]
Mas, se tiver acesso a uma função de redução, pode escrevê - la assim
A = [7, 8, 9]
sum = A.reduce( 0, (x, y) => x + y )
Agora é um pouco confuso porque há 2 argumentos (0 e a função com x e passei. Para que uma função de redução seja útil, ela deve ser capaz de levar 2 itens, calcular algo e "reduzir" que 2 itens para apenas um único valor, assim o programa poderia reduzir cada par até que tenhamos um único valor.
A execução seria a seguinte:
result = 0
7 : result = result + 7 = 0 + 7 = 7
8 : result = result + 8 = 7 + 8 = 15
9 : result = result + 9 = 15 + 9 = 24
Mas você não quer começar com zeros o tempo todo, então o primeiro argumento está lá para permitir que você especifique um valor de semente especificamente o valor na primeira linha result =.
A = [7, 8, 9]
B = [1, 2, 3]
sum = 0
sum = A.reduce( sum, (x, y) => x + y )
sum = B.reduce( sum, (x, y) => x + y )
A = [7, 8, 9]
B = [1, 2, 3]
sum_func = (x, y) => x + y
sum = A.reduce( B.reduce( 0, sum_func ), sum_func )
É uma coisa boa em um software DB porque, com o Map \ reduzir o suporte você pode trabalhar com o banco de dados sem precisar saber como os dados são armazenados em um DB para usá-lo, é para isso que um motor DB é.
Você só precisa ser capaz de "dizer" ao motor o que você quer, fornecendo-lhes um mapa ou uma função de redução e, em seguida, o motor DB pode encontrar o seu caminho em torno os dados, aplicar sua função, e chegar com os resultados que você quer tudo sem você saber como ele loops em todos os registros.
Existem índices e chaves e juntas e vistas e um monte de coisas que uma única base de dados poderia manter, então, protegendo-o contra como os dados são realmente armazenados, o seu código é mais fácil de escrever e manter.
O mesmo vale para programação paralela, se você só especificar o que você quer fazer com os dados em vez de realmente implementar o looping código, então a infra-estrutura subjacente poderia "paralelizar" e executar sua função em um ciclo paralelo simultâneo para você.
MapReduce é um método para processar vastas somas de dados em paralelo, sem exigir que o programador escreva qualquer outro código que não o mapeador e reduza funções.
A funçãomap recebe dados e produz um resultado, que é mantido numa barreira. Esta função pode ser executada em paralelo com um grande número da mesma tarefa do mapa. O conjunto de dados pode então ser reduzido para um valor escalar.
Então, se pensares nisso como uma declaração SQLSELECT SUM(salary)
FROM employees
WHERE salary > 1000
GROUP by deptname
Podemos usar o mapa para obter o nosso subconjunto de empregados com salário > 1000 que o mapa emite para a barreira em baldes de tamanho de grupo.
Reduzir somará cada um desses grupos. Dando-lhe o seu conjunto de resultados.
acabei de tirar isto da minha universidade. notas de estudo do google paper.
- Pegue um monte de dados
- realizar algum tipo de transformação que converte cada dado para outro tipo de dado
- combinar esses novos dados em dados ainda mais simples
O Passo 2 é o mapa. Passo 3 é reduzir.
Por exemplo,
-
Arranja tempo entre dois impulsos num par de medidores de pressão na estrada.
- mapeia esses tempos em velocidades baseadas na distância dos metros
- reduzir essas velocidades para uma média velocidade
Para uma descrição complexa mas boa do MapReduce, veja: O modelo de programação MapReduce do Google -- Revisited (PDF).
Imagine que você tem uma lista de cidades com informações sobre o nome, número de pessoas que vivem lá e o tamanho da cidade:
(defparameter *cities*
'((a :people 100000 :size 200)
(b :people 200000 :size 300)
(c :people 150000 :size 210)))
Agora você pode querer encontrar a cidade com a maior densidade populacional.
Primeiro criamos uma lista de nomes de cidades e densidade populacional usando o mapa:(map 'list
(lambda (city)
(list (first city)
(/ (getf (rest city) :people)
(getf (rest city) :size))))
*cities*)
=> ((A 500) (B 2000/3) (C 5000/7))
(reduce (lambda (a b)
(if (> (second a) (second b))
a
b))
'((A 500) (B 2000/3) (C 5000/7)))
=> (C 5000/7)
(reduce (lambda (a b)
(if (> (second a) (second b))
a
b))
(map 'list
(lambda (city)
(list (first city)
(/ (getf (rest city) :people)
(getf (rest city) :size))))
*cities*))
(defun density (city)
(list (first city)
(/ (getf (rest city) :people)
(getf (rest city) :size))))
(defun max-density (a b)
(if (> (second a) (second b))
a
b))
(reduce 'max-density
(map 'list 'density *cities*))
=> (C 5000/7)
Chama-se MAP e REDUCE (a avaliação Está do avesso), por isso chama-seredução do mapa .
A really easy, quick and "for dummies" introduction to MapReduce is available at: http://www.marcolotz.com/?p=67
Postando parte do conteúdo:
Em primeiro lugar, porque é que o MapReduce foi criado originalmente?
Basicamente o Google precisava de uma solução para fazer grandes trabalhos de computação facilmente paralelizáveis, permitindo que os dados fossem distribuídos em um número de máquinas conectadas através de uma rede. Além disso, teve de lidar com a falha da máquina de uma forma transparente e gerenciar problemas de equilíbrio de carga.
Quais são os verdadeiros pontos fortes do MapReduce?
Pode-se dizer que a magia do MapReduce é baseada no mapa e reduz a aplicação de funções. Devo confessar que discordo totalmente. A principal característica que tornou o MapReduce tão popular é a sua capacidade de paralelização e distribuição automática, combinada com a interface simples. Estes factores somaram-se com um tratamento transparente de falhas para a maioria dos erros que tornaram este quadro tão popular.Um pouco mais de profundidade no papel:
MapReduce foi originalmente mencionado em um Google paper (Dean & Ghemawat, 2004 – link aqui) como uma solução para fazer cálculos em grandes dados usando uma abordagem paralela e clusters commodity-computer. Em contraste com o Hadoop, que é escrito em Java, o framework do Google é escrito em C++. O documento descreve como uma estrutura paralela se comportaria usando o mapa e reduziria as funções de programação funcional sobre grandes conjuntos de dados. Nesta solução haveria dois passos principais - chamado mapa e redução–, com um passo opcional entre a primeira e a segunda-chamada combinação. O passo do mapa seria executado primeiro, fazer cálculos no par chave-valor de entrada e gerar um novo valor-chave de saída. Deve-se ter em mente que o formato dos pares chave-valor de entrada não precisa necessariamente corresponder ao par de formato de saída. A etapa de redução reuniria todos os valores do a mesma chave, executando outros cálculos sobre ela. Como resultado, esta última etapa produziria pares chave-valor. Uma das aplicações mais triviais do MapReduce é implementar contagens de palavras.O pseudo-código para esta aplicação, é dado abaixo:
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, “1”);
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));
Como se pode notar, o mapa lê todas as palavras em um registro (neste caso, um registro pode ser uma linha) e emite a palavra-chave e o número 1 como o valor. Mais tarde, a redução irá agrupar todos os valores da mesma chave. Vamos dar um exemplo: imagine que a palavra "casa" aparece três vezes no registro. A entrada do redutor seria [casa, [1,1,1]]. No redutor, somará todos os valores para a casa de chaves e dará como saída o seguinte valor chave: [casa, [3]].
Aqui está uma imagem de como isso seria em um framework MapReduce: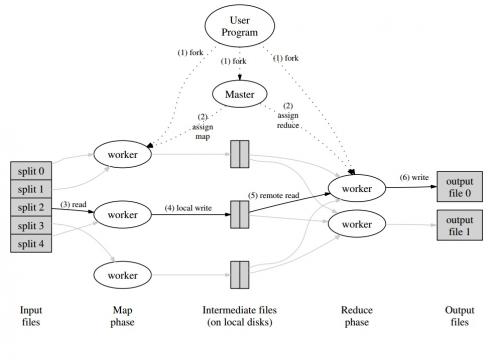
Como alguns outros exemplos clássicos de aplicações MapReduce, pode-se dizer:
* Número de acesso ao URL frequência
* grafo de ligação reversa na Web
•Grep Distribuído
* Termo Vector por hospedeiro
A fim de evitar muito tráfego de rede, o documento descreve como o framework deve tentar manter a localidade de dados. Isto significa que ele deve sempre tentar se certificar de que uma máquina executando tarefas de mapa tem os dados em sua memória/armazenamento local, evitando busca-lo a partir da rede. Com o objetivo de reduzir a rede através de put de um mapeador, o passo combinador opcional, descrito anteriormente, é utilizado. O combinador executa cálculos sobre a saída dos mapeadores em uma determinada máquina antes de enviá – lo para os redutores-que pode estar em outra máquina.
O documento também descreve como os elementos da estrutura devem comportar-se em caso de falhas. Estes elementos, no jornal, são chamados de trabalhadores e mestres. Eles serão divididos em elementos mais específicos em implementações de código aberto. Uma vez que o Google só descreveu a abordagem no papel e não liberou seu software proprietário, muitos frameworks de código aberto foram criados para implementar o modelo. Como exemplos pode-se dizer Hadoop ou a característica MapReduce limitada em MongoDB.
O tempo de execução deve cuidar de detalhes de programadores não especialistas, como particionar os dados de entrada, agendar a execução do programa através do grande conjunto de máquinas, manusear falhas de máquinas (de uma forma transparente, é claro) e gerenciar a comunicação entre máquinas. Um utilizador experiente pode afine estes parâmetros, como a forma como os dados de entrada serão divididos entre os trabalhadores.
Conceitos-Chave:
•tolerância à falha: deve tolerar a falha da máquina graciosamente. Para isso, o mestre espalha os operários periodicamente. Se o mestre não receber respostas de um determinado Operário num determinado lapso de tempo, o mestre definirá a obra como falhada nesse Operário. Neste caso, todas as tarefas de mapa completadas pelo trabalhador defeituoso são descartadas e são dadas a outro trabalhador disponível. Semelhante acontece se o trabalhador ainda estava processando um mapa ou uma tarefa de redução. Note que se o trabalhador já completou sua parte de redução, todo o cálculo já estava terminado no momento em que falhou e não precisa ser reiniciado. Como ponto primário de fracasso, se o mestre falha, todo o trabalho falha. Por esta razão, pode-se definir pontos de controle periódicos para o mestre, a fim de salvar sua estrutura de dados. Todos os cálculos que acontecem entre o último ponto de controlo e o fracasso Mestre está perdido.
•localidade: a fim de evitar o tráfego de rede, o framework tenta certificar-se de que todos os dados de entrada estão localmente disponíveis para as máquinas que vão realizar cálculos sobre eles. Na descrição original, ele usa o Google File System (GFS) com fator de replicação definido para 3 e tamanhos de bloco de 64 MB. Isto significa que o mesmo bloco de 64 MB (que compõe um arquivo no sistema de arquivos) terá cópias idênticas em três diferentes Niquel. O mestre sabe onde estão os blocos e tentar agendar trabalhos de mapa nessa máquina. Se isso falhar, o mestre tenta alocar uma máquina perto de uma réplica dos dados de entrada de tarefas (ou seja, uma máquina de trabalho no mesmo rack da máquina de dados).
•granularidade da Tarefa: assumindo que cada fase do mapa é dividida em peças M e que cada fase de redução é dividida em peças R, O ideal Seria que M E R são muito maiores do que o número de máquinas de trabalho. Isto é devido ao o fato de um trabalhador realizar muitas tarefas diferentes melhora o equilíbrio dinâmico da carga. Além disso, aumenta a velocidade de recuperação no caso de falha do trabalhador (uma vez que as muitas tarefas de mapa que completou pode ser espalhado por todas as outras máquinas).
•tarefas de Backup: Às vezes, um trabalhador de mapa ou redutor pode se comportar muito mais lento do que os outros no grupo. Isto pode manter o tempo total de processamento e torná-lo igual ao tempo de processamento dessa única máquina lenta. O o artigo original descreve uma alternativa chamada Tarefas de Backup, que são agendadas pelo mestre quando uma operação MapReduce está perto da conclusão. Trata-se de tarefas programadas pelo Mestre das tarefas em curso. Assim, a operação MapReduce completa quando o primário ou o backup termina.
•contadores: Às vezes pode-se desejar contar ocorrências de eventos. Por esta razão, conta onde foi criado. Os contra-valores em cada trabalhador são periodicamente propagados ao mestre. O mestre então agrega (Yep. Parece que agregadores de Pregel vieram deste lugar ) os valores de contador de um mapa de sucesso e reduzir a tarefa e devolvê-los ao código do usuário quando a operação MapReduce está completa. Há também um valor de contador atual disponível no estado mestre, de modo que um humano observando o processo pode manter o controle de como ele está se comportando.
Bem, acho que com todos os conceitos acima, o Hadoop vai ser canja para ti. Se tiver alguma pergunta sobre o artigo original do MapReduce ou algo relacionado, por favor, avise-me.cat input | map | reduce > output
Se você está familiarizado com Python, a seguir está a explicação mais simples possível do MapReduce:
In [2]: data = [1, 2, 3, 4, 5, 6]
In [3]: mapped_result = map(lambda x: x*2, data)
In [4]: mapped_result
Out[4]: [2, 4, 6, 8, 10, 12]
In [10]: final_result = reduce(lambda x, y: x+y, mapped_result)
In [11]: final_result
Out[11]: 42
Veja como cada segmento de dados brutos foi processado individualmente, neste caso, multiplicado por 2 (a parte do mapa {[13] } do MapReduce). Com base no mapped_result, concluímos que o resultado seria 42 (a redução da parte do MapReduce).
Uma conclusão importante deste exemplo é o facto de cada pedaço de processamento não depender de outro pedaço. Para exemplo, se thread_1 mapas [1, 2, 3], e thread_2 mapas [4, 5, 6], o resultado final de ambos os segmentos ainda seria [2, 4, 6, 8, 10, 12] mas temos que metade o tempo de processamento para isso. O mesmo pode ser dito para a operação de redução e é a essência de como MapReduce funciona em computação paralela.