Raspar a tabela do sítio web [timeanddate.com]
Este é o link do sítio web: https://www.timeanddate.com/weather/usa/dayton/historic?month=2&year=2016 aqui estou eu selecionando fevereiro e 2016, e o resultado aparecerá no final da página.
usei os seguintes passos: https://stackoverflow.com/a/47280970/9341589
E está a funcionar perfeitamente no primeiro dia de cada um. mês ", quero analisar todo o mês, e se for possível durante todo o ano.abaixo do código que estou a usar (para analisar Março 1, 2016):
from urllib.request import urlopen
from bs4 import BeautifulSoup
url = "https://www.timeanddate.com/weather/usa/dayton/historic?month=3&year=2016"
page = urlopen(url)
soup = BeautifulSoup(page, "html.parser")
Data = []
table = soup.find('table', attrs={'id':'wt-his'})
for tr in table.find('tbody').find_all('tr'):
dict = {}
dict['time'] = tr.find('th').text.strip()
all_td = tr.find_all('td')
dict['temp'] = all_td[1].text
dict['weather'] = all_td[2].text
dict['wind'] = all_td[3].text
arrow = all_td[4].text
dict['humidity'] = all_td[5].text
dict['barometer'] = all_td[6].text
dict['visibility'] = all_td[7].text
Data.append(dict)
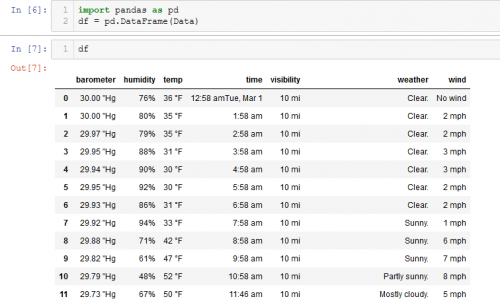
isto é porque o site "url", o link só inclui o mês e ano, e para mudar os dias, por exemplo, de Feb1 para fev 3, a página é mostrada no pic anexado necessário para ser usado:
2 answers
Você pode iterar sobre os elementos da tabela (tr, th, e td) para uma única página:
import requests, re, typing
from bs4 import BeautifulSoup as soup
import contextlib
def _remove(d:list) -> list:
return list(filter(None, [re.sub('\xa0', '', b) for b in d]))
@contextlib.contextmanager
def get_weather_data(url:str, by_url = True) -> typing.Generator[dict, None, None]:
d = soup(requests.get(url).text if by_url else url, 'html.parser')
_table = d.find('table', {'id':'wt-his'})
_data = [[[i.text for i in c.find_all('th')], *[i.text for i in c.find_all('td')]] for c in _table.find_all('tr')]
[h1], [h2], *data, _ = _data
_h2 = _remove(h2)
yield {tuple(_remove(h1)):[dict(zip(_h2, _remove([a, *i]))) for [[a], *i] in data]}
with get_weather_data('https://www.timeanddate.com/weather/usa/dayton/historic?month=2&year=2016') as weather:
print(weather)
Resultado:
{('Conditions', 'Comfort'): [{'Time': '12:58 amMon, Feb 1', 'Temp': '50°F', 'Weather': 'Light rain. Mostly cloudy.', 'Wind': '13 mph', 'Humidity': '↑', 'Barometer': '88%', 'Visibility': '29.79 "Hg'}, {'Time': '1:58 am', 'Temp': '46°F', 'Weather': 'Mostly cloudy.', 'Wind': '12 mph', 'Humidity': '↑', 'Barometer': '83%', 'Visibility': '29.82 "Hg'}, {'Time': '2:58 am', 'Temp': '43°F', 'Weather': 'Mostly cloudy.', 'Wind': '14 mph', 'Humidity': '↑', 'Barometer': '85%', 'Visibility': '29.87 "Hg'}, {'Time': '3:58 am', 'Temp': '42°F', 'Weather': 'Mostly cloudy.', 'Wind': '10 mph', 'Humidity': '↑', 'Barometer': '83%', 'Visibility': '29.89 "Hg'}, {'Time': '4:58 am', 'Temp': '41°F', 'Weather': 'Mostly cloudy.', 'Wind': '10 mph', 'Humidity': '↑', 'Barometer': '82%', 'Visibility': '29.91 "Hg'}, {'Time': '5:58 am', 'Temp': '39°F', 'Weather': 'Mostly cloudy.', 'Wind': '8 mph', 'Humidity': '↑', 'Barometer': '83%', 'Visibility': '29.93 "Hg'}, {'Time': '6:58 am', 'Temp': '38°F', 'Weather': 'Partly cloudy.', 'Wind': '5 mph', 'Humidity': '↑', 'Barometer': '82%', 'Visibility': '29.96 "Hg'}, {'Time': '7:58 am', 'Temp': '38°F', 'Weather': 'Partly sunny.', 'Wind': '5 mph', 'Humidity': '↑', 'Barometer': '80%', 'Visibility': '29.99 "Hg'}, {'Time': '8:58 am', 'Temp': '38°F', 'Weather': 'Overcast.', 'Wind': '5 mph', 'Humidity': '↑', 'Barometer': '78%', 'Visibility': '30.01 "Hg'}, {'Time': '9:58 am', 'Temp': '40°F', 'Weather': 'Broken clouds.', 'Wind': '7 mph', 'Humidity': '↑', 'Barometer': 'N/A', 'Visibility': '30.01 "Hg'}, {'Time': '10:58 am', 'Temp': '41°F', 'Weather': 'Broken clouds.', 'Wind': '1 mph', 'Humidity': '↑', 'Barometer': '72%', 'Visibility': '30.02 "Hg'}, {'Time': '11:58 am', 'Temp': '41°F', 'Weather': 'Partly sunny.', 'Wind': '2 mph', 'Humidity': '↑', 'Barometer': '70%', 'Visibility': '30.04 "Hg'}, {'Time': '12:58 pm', 'Temp': '42°F', 'Weather': 'Scattered clouds.', 'Wind': '2 mph', 'Humidity': '↑', 'Barometer': '69%', 'Visibility': '30.04 "Hg'}, {'Time': '1:58 pm', 'Temp': '43°F', 'Weather': 'Partly sunny.', 'Wind': '3 mph', 'Humidity': '↑', 'Barometer': '65%', 'Visibility': '30.03 "Hg'}, {'Time': '2:58 pm', 'Temp': '44°F', 'Weather': 'Partly sunny.', 'Wind': 'No wind', 'Humidity': '↑', 'Barometer': '62%', 'Visibility': '30.02 "Hg'}, {'Time': '3:58 pm', 'Temp': '46°F', 'Weather': 'Passing clouds.', 'Wind': '6 mph', 'Humidity': '↑', 'Barometer': '58%', 'Visibility': '30.03 "Hg'}, {'Time': '4:58 pm', 'Temp': '46°F', 'Weather': 'Sunny.', 'Wind': '6 mph', 'Humidity': '↑', 'Barometer': '57%', 'Visibility': '30.04 "Hg'}, {'Time': '5:58 pm', 'Temp': '43°F', 'Weather': 'Clear.', 'Wind': '3 mph', 'Humidity': '↑', 'Barometer': '65%', 'Visibility': '30.06 "Hg'}, {'Time': '6:58 pm', 'Temp': '39°F', 'Weather': 'Clear.', 'Wind': '1 mph', 'Humidity': '↑', 'Barometer': '71%', 'Visibility': '30.09 "Hg'}, {'Time': '7:58 pm', 'Temp': '35°F', 'Weather': 'Clear.', 'Wind': '1 mph', 'Humidity': '↑', 'Barometer': '79%', 'Visibility': '30.11 "Hg'}, {'Time': '8:58 pm', 'Temp': '32°F', 'Weather': 'Clear.', 'Wind': 'No wind', 'Humidity': '↑', 'Barometer': '85%', 'Visibility': '30.13 "Hg'}, {'Time': '9:58 pm', 'Temp': '30°F', 'Weather': 'Clear.', 'Wind': 'No wind', 'Humidity': '↑', 'Barometer': '91%', 'Visibility': '30.14 "Hg'}, {'Time': '10:58 pm', 'Temp': '28°F', 'Weather': 'Clear.', 'Wind': '5 mph', 'Humidity': '↑', 'Barometer': '93%', 'Visibility': '30.14 "Hg'}, {'Time': '11:58 pm', 'Temp': '29°F', 'Weather': 'Clear.', 'Wind': 'No wind', 'Humidity': '↑', 'Barometer': '90%', 'Visibility': '30.13 "Hg'}]}
No entanto, para raspar os dados para todos os dias do mês desejado, selenium deve ser usado, uma vez que o site actualiza dinamicamente o DOM através de um pedido à infra-estrutura:
from selenium import webdriver
d = webdriver.Chrome('/Path/to/chromedriver')
d.get('https://www.timeanddate.com/weather/usa/dayton/historic?month=2&year=2016')
_d = {}
for i in d.find_element_by_id('wt-his-select').find_elements_by_tag_name('option'):
i.click()
with get_weather_data(d.page_source, False) as weather:
_d[i.text] = weather
Editar: para iterar os resultados completos dos dados, use dict.items:
for a, b in _d.items():
pass #do something with a and b
Usando as ferramentas de desenvolvimento no chrome, parece que pode procurar e carregar numa ligação com o texto {[[0]} usando driver.find_element_by_link_text(date_here).click()