Como usar a roscagem em Python?
Como é que mostra claramente as tarefas que estão a ser divididas para multi-threading?
17 answers
Desde que esta pergunta foi feita em 2010, tem havido uma simplificação real em como fazer multithreading simples com python com Mapa e pool.
O código abaixo vem de um artigo / blog post que você definitivamente deve verificar (sem afiliação) - paralelismo numa linha: Um modelo melhor para tarefas de Threading dia-a-dia. Vou resumir a seguir-acaba por ser apenas algumas linhas de código:
from multiprocessing.dummy import Pool as ThreadPool
pool = ThreadPool(4)
results = pool.map(my_function, my_array)
Que é a versão multithreaded de:
results = []
for item in my_array:
results.append(my_function(item))
Designação das mercadorias
O mapa é uma pequena função fixe, e a chave para injectar facilmente o paralelismo no seu código Python. Para aqueles desconhecidos, o mapa é algo retirado de linguagens funcionais como Lisp. É uma função que mapeia outra função sobre uma sequência.
O mapa lida com a iteração sobre a sequência para nós, aplica a função, e guarda todos os resultados numa lista útil no fim.
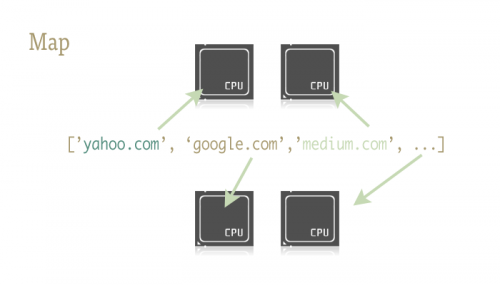
Execução
As versões paralelas da função mapa são fornecidas por duas bibliotecas:multiprocessamento, e também o seu pouco conhecido, mas igualmente fantástico filho passo:multiprocessamento.manequim.
multiprocessing.dummy é exactamente o mesmo que o módulo multiprocessador, mas usa os tópicos em vez disso (uma distinção importante - usar vários processos para tarefas intensivas de CPU; tópicos para (e durante) IO):
Multiprocessamento.o manequim replica a API do multiprocessamento, mas não é mais do que um invólucro em torno do módulo de rosca.
import urllib2
from multiprocessing.dummy import Pool as ThreadPool
urls = [
'http://www.python.org',
'http://www.python.org/about/',
'http://www.onlamp.com/pub/a/python/2003/04/17/metaclasses.html',
'http://www.python.org/doc/',
'http://www.python.org/download/',
'http://www.python.org/getit/',
'http://www.python.org/community/',
'https://wiki.python.org/moin/',
]
# make the Pool of workers
pool = ThreadPool(4)
# open the urls in their own threads
# and return the results
results = pool.map(urllib2.urlopen, urls)
# close the pool and wait for the work to finish
pool.close()
pool.join()
E os resultados temporais:
Single thread: 14.4 seconds
4 Pool: 3.1 seconds
8 Pool: 1.4 seconds
13 Pool: 1.3 seconds
Passando vários argumentos (funciona como este apenas no Python 3.3 e mais tarde):
Para passar por várias matrizes:
results = pool.starmap(function, zip(list_a, list_b))
results = pool.starmap(function, zip(itertools.repeat(constant), list_a))
Se estiver a utilizar uma versão anterior de Python, você pode passar vários argumentos através de este workaround .
(Graças a user136036 para o comentário útil)
Aqui está um exemplo simples: você precisa experimentar alguns URLs alternativos e devolver o conteúdo do primeiro a responder.
import Queue
import threading
import urllib2
# called by each thread
def get_url(q, url):
q.put(urllib2.urlopen(url).read())
theurls = ["http://google.com", "http://yahoo.com"]
q = Queue.Queue()
for u in theurls:
t = threading.Thread(target=get_url, args = (q,u))
t.daemon = True
t.start()
s = q.get()
print s
Este é um caso onde enfiar é usado como uma otimização simples: cada subthread está esperando por uma URL para resolver e responder, para colocar seu conteúdo na fila; cada linha é um daemon (não manter o processo até se thread principal termina, isso é mais comum do que não); a thread principal inicia todos os subthreads, faz um get na fila de espera até que um deles fez um put, em seguida, emite os resultados e termina (que retira todas as sub-linhas que ainda podem estar em execução, uma vez que eles são threads do daemon).
O uso adequado de threads em Python está invariavelmente ligado a operações de I/O (Uma vez que o CPython não usa múltiplos núcleos para executar tarefas de ligação de CPU de qualquer forma, a única razão para a threading não é bloquear o processo enquanto há uma espera por algum I/O). Filas são quase invariavelmente a melhor maneira de cultivar o trabalho para threads e / ou coletar os resultados do trabalho, a propósito, e eles são intrinsecamente threadsafe para que eles o salvem de se preocupar com bloqueios, condições, eventos, semáforos, e outros conceitos de coordenação/comunicação inter-thread.
OBSERVAÇÃO: real paralelização em Python, você deve usar o multiprocessamento módulo de bifurcação de vários processos que executam em paralelo (devido ao global intérprete de bloqueio, Python threads fornecer intercalação mas na verdade são executadas em série, nem em paralelo, e só são úteis quando intercalação de operações de e/S).
No entanto, se está apenas à procura de interlaving (ou está a fazer operações de E / S que podem ser paralelas apesar do interpretador global lock), então o módulothreading é o lugar para começar. Como um exemplo realmente simples, vamos considerar o problema de somar um grande intervalo somando sub-mudanças em paralelo:import threading
class SummingThread(threading.Thread):
def __init__(self,low,high):
super(SummingThread, self).__init__()
self.low=low
self.high=high
self.total=0
def run(self):
for i in range(self.low,self.high):
self.total+=i
thread1 = SummingThread(0,500000)
thread2 = SummingThread(500000,1000000)
thread1.start() # This actually causes the thread to run
thread2.start()
thread1.join() # This waits until the thread has completed
thread2.join()
# At this point, both threads have completed
result = thread1.total + thread2.total
print result
Note que o acima é um exemplo muito estúpido, uma vez que não faz absolutamente nenhum I/O e será executado em série, embora intercalado (com a sobrecarga adicionada de mudança de contexto) no CPython devido ao bloqueio global do interpretador.
from multiprocessing import Process
def f(name):
print 'hello', name
if __name__ == '__main__':
p = Process(target=f, args=('bob',))
p.start()
p.join()
Apenas uma nota, A fila não é necessária para a roscagem.
Este é o exemplo mais simples que eu poderia imaginar que mostra 10 processos funcionando simultaneamente.
import threading
from random import randint
from time import sleep
def print_number(number):
# Sleeps a random 1 to 10 seconds
rand_int_var = randint(1, 10)
sleep(rand_int_var)
print "Thread " + str(number) + " slept for " + str(rand_int_var) + " seconds"
thread_list = []
for i in range(1, 10):
# Instantiates the thread
# (i) does not make a sequence, so (i,)
t = threading.Thread(target=print_number, args=(i,))
# Sticks the thread in a list so that it remains accessible
thread_list.append(t)
# Starts threads
for thread in thread_list:
thread.start()
# This blocks the calling thread until the thread whose join() method is called is terminated.
# From http://docs.python.org/2/library/threading.html#thread-objects
for thread in thread_list:
thread.join()
# Demonstrates that the main process waited for threads to complete
print "Done"
import Queue
import threading
import urllib2
worker_data = ['http://google.com', 'http://yahoo.com', 'http://bing.com']
#load up a queue with your data, this will handle locking
q = Queue.Queue()
for url in worker_data:
q.put(url)
#define a worker function
def worker(queue):
queue_full = True
while queue_full:
try:
#get your data off the queue, and do some work
url= queue.get(False)
data = urllib2.urlopen(url).read()
print len(data)
except Queue.Empty:
queue_full = False
#create as many threads as you want
thread_count = 5
for i in range(thread_count):
t = threading.Thread(target=worker, args = (q,))
t.start()
Achei isto muito útil: criar tantos threads como núcleos e deixá-los executar um (grande) número de tarefas (neste caso, chamando um programa de shell):
import Queue
import threading
import multiprocessing
import subprocess
q = Queue.Queue()
for i in range(30): #put 30 tasks in the queue
q.put(i)
def worker():
while True:
item = q.get()
#execute a task: call a shell program and wait until it completes
subprocess.call("echo "+str(item), shell=True)
q.task_done()
cpus=multiprocessing.cpu_count() #detect number of cores
print("Creating %d threads" % cpus)
for i in range(cpus):
t = threading.Thread(target=worker)
t.daemon = True
t.start()
q.join() #block until all tasks are done
# thread_test.py
import threading
import time
class Monitor(threading.Thread):
def __init__(self, mon):
threading.Thread.__init__(self)
self.mon = mon
def run(self):
while True:
if self.mon[0] == 2:
print "Mon = 2"
self.mon[0] = 3;
Você pode jogar com este código abrindo uma sessão de IPython e fazendo algo como:
>>>from thread_test import Monitor
>>>a = [0]
>>>mon = Monitor(a)
>>>mon.start()
>>>a[0] = 2
Mon = 2
>>>a[0] = 2
Mon = 2
>>>a[0] = 2
Mon = 2
Dada uma função, f, rode-a assim:
import threading
threading.Thread(target=f).start()
Para passar os argumentos para f
threading.Thread(target=f, args=(a,b,c)).start()
O Python 3 tem a facilidade de lançar tarefas paralelas . Isto torna o nosso trabalho mais fácil.
Tem para reunião de fios e reunião de Processos.
O seguinte dá uma ideia:
Exemplo ThreadPoolExecutor
import concurrent.futures
import urllib.request
URLS = ['http://www.foxnews.com/',
'http://www.cnn.com/',
'http://europe.wsj.com/',
'http://www.bbc.co.uk/',
'http://some-made-up-domain.com/']
# Retrieve a single page and report the URL and contents
def load_url(url, timeout):
with urllib.request.urlopen(url, timeout=timeout) as conn:
return conn.read()
# We can use a with statement to ensure threads are cleaned up promptly
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
# Start the load operations and mark each future with its URL
future_to_url = {executor.submit(load_url, url, 60): url for url in URLS}
for future in concurrent.futures.as_completed(future_to_url):
url = future_to_url[future]
try:
data = future.result()
except Exception as exc:
print('%r generated an exception: %s' % (url, exc))
else:
print('%r page is %d bytes' % (url, len(data)))
ProcessPoolExecutor
import concurrent.futures
import math
PRIMES = [
112272535095293,
112582705942171,
112272535095293,
115280095190773,
115797848077099,
1099726899285419]
def is_prime(n):
if n % 2 == 0:
return False
sqrt_n = int(math.floor(math.sqrt(n)))
for i in range(3, sqrt_n + 1, 2):
if n % i == 0:
return False
return True
def main():
with concurrent.futures.ProcessPoolExecutor() as executor:
for number, prime in zip(PRIMES, executor.map(is_prime, PRIMES)):
print('%d is prime: %s' % (number, prime))
if __name__ == '__main__':
main()
Usando o novo em chamas.futuros Módulo
def sqr(val):
import time
time.sleep(0.1)
return val * val
def process_result(result):
print(result)
def process_these_asap(tasks):
import concurrent.futures
with concurrent.futures.ProcessPoolExecutor() as executor:
futures = []
for task in tasks:
futures.append(executor.submit(sqr, task))
for future in concurrent.futures.as_completed(futures):
process_result(future.result())
# Or instead of all this just do:
# results = executor.map(sqr, tasks)
# list(map(process_result, results))
def main():
tasks = list(range(10))
print('Processing {} tasks'.format(len(tasks)))
process_these_asap(tasks)
print('Done')
return 0
if __name__ == '__main__':
import sys
sys.exit(main())
Também numa nota lateral: para manter o universo são, não se esqueça de fechar as suas piscinas / executores se não usar o contexto with (o que é tão incrível que o faz por si)
Threading e Queue podem parecer avassaladores para iniciantes.
Talvez considere o Módulo concurrent.futures.ThreadPoolExecutor do python 3.
Combinado com a cláusula with e a compreensão da lista, pode ser um verdadeiro encanto.
from concurrent.futures import ThreadPoolExecutor, as_completed
def get_url(url):
# Your actual program here. Using threading.Lock() if necessary
return ""
# List of urls to fetch
urls = ["url1", "url2"]
with ThreadPoolExecutor(max_workers = 5) as executor:
# Create threads
futures = {executor.submit(get_url, url) for url in urls}
# as_completed() gives you the threads once finished
for f in as_completed(futures):
# Get the results
rs = f.result()
Aqui está o exemplo muito simples de importação CSV usando threading. [A inclusão na biblioteca pode diferir para fins diferentes]
Funções Auxiliares:
from threading import Thread
from project import app
import csv
def import_handler(csv_file_name):
thr = Thread(target=dump_async_csv_data, args=[csv_file_name])
thr.start()
def dump_async_csv_data(csv_file_name):
with app.app_context():
with open(csv_file_name) as File:
reader = csv.DictReader(File)
for row in reader:
#DB operation/query
Função Do Condutor:
import_handler(csv_file_name)
Multi threading com exemplo simples que será útil. Você pode executá-lo e entender facilmente como é multi thread trabalhando em python. Eu usei bloqueio para impedir o acesso a outro tópico até que os tópicos anteriores terminaram o seu trabalho. Pela utilização de
TLock = threading.Encadernação (valor=4)
Esta linha de código você pode permitir números de processo de uma vez e manter o resto do tópico que irá correr mais tarde ou depois de terminar os processos anteriores.
import threading
import time
#tLock = threading.Lock()
tLock = threading.BoundedSemaphore(value=4)
def timer(name, delay, repeat):
print "\r\nTimer: ", name, " Started"
tLock.acquire()
print "\r\n", name, " has the acquired the lock"
while repeat > 0:
time.sleep(delay)
print "\r\n", name, ": ", str(time.ctime(time.time()))
repeat -= 1
print "\r\n", name, " is releaseing the lock"
tLock.release()
print "\r\nTimer: ", name, " Completed"
def Main():
t1 = threading.Thread(target=timer, args=("Timer1", 2, 5))
t2 = threading.Thread(target=timer, args=("Timer2", 3, 5))
t3 = threading.Thread(target=timer, args=("Timer3", 4, 5))
t4 = threading.Thread(target=timer, args=("Timer4", 5, 5))
t5 = threading.Thread(target=timer, args=("Timer5", 0.1, 5))
t1.start()
t2.start()
t3.start()
t4.start()
t5.start()
print "\r\nMain Complete"
if __name__ == "__main__":
Main()
import math
import timeit
import threading
import multiprocessing
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
def time_stuff(fn):
"""
Measure time of execution of a function
"""
def wrapper(*args, **kwargs):
t0 = timeit.default_timer()
fn(*args, **kwargs)
t1 = timeit.default_timer()
print("{} seconds".format(t1 - t0))
return wrapper
def find_primes_in(nmin, nmax):
"""
Compute a list of prime numbers between the given minimum and maximum arguments
"""
primes = []
#Loop from minimum to maximum
for current in range(nmin, nmax + 1):
#Take the square root of the current number
sqrt_n = int(math.sqrt(current))
found = False
#Check if the any number from 2 to the square root + 1 divides the current numnber under consideration
for number in range(2, sqrt_n + 1):
#If divisible we have found a factor, hence this is not a prime number, lets move to the next one
if current % number == 0:
found = True
break
#If not divisible, add this number to the list of primes that we have found so far
if not found:
primes.append(current)
#I am merely printing the length of the array containing all the primes but feel free to do what you want
print(len(primes))
@time_stuff
def sequential_prime_finder(nmin, nmax):
"""
Use the main process and main thread to compute everything in this case
"""
find_primes_in(nmin, nmax)
@time_stuff
def threading_prime_finder(nmin, nmax):
"""
If the minimum is 1000 and the maximum is 2000 and we have 4 workers
1000 - 1250 to worker 1
1250 - 1500 to worker 2
1500 - 1750 to worker 3
1750 - 2000 to worker 4
so lets split the min and max values according to the number of workers
"""
nrange = nmax - nmin
threads = []
for i in range(8):
start = int(nmin + i * nrange/8)
end = int(nmin + (i + 1) * nrange/8)
#Start the thrread with the min and max split up to compute
#Parallel computation will not work here due to GIL since this is a CPU bound task
t = threading.Thread(target = find_primes_in, args = (start, end))
threads.append(t)
t.start()
#Dont forget to wait for the threads to finish
for t in threads:
t.join()
@time_stuff
def processing_prime_finder(nmin, nmax):
"""
Split the min, max interval similar to the threading method above but use processes this time
"""
nrange = nmax - nmin
processes = []
for i in range(8):
start = int(nmin + i * nrange/8)
end = int(nmin + (i + 1) * nrange/8)
p = multiprocessing.Process(target = find_primes_in, args = (start, end))
processes.append(p)
p.start()
for p in processes:
p.join()
@time_stuff
def thread_executor_prime_finder(nmin, nmax):
"""
Split the min max interval similar to the threading method but use thread pool executor this time
This method is slightly faster than using pure threading as the pools manage threads more efficiently
This method is still slow due to the GIL limitations since we are doing a CPU bound task
"""
nrange = nmax - nmin
with ThreadPoolExecutor(max_workers = 8) as e:
for i in range(8):
start = int(nmin + i * nrange/8)
end = int(nmin + (i + 1) * nrange/8)
e.submit(find_primes_in, start, end)
@time_stuff
def process_executor_prime_finder(nmin, nmax):
"""
Split the min max interval similar to the threading method but use the process pool executor
This is the fastest method recorded so far as it manages process efficiently + overcomes GIL limitations
RECOMMENDED METHOD FOR CPU BOUND TASKS
"""
nrange = nmax - nmin
with ProcessPoolExecutor(max_workers = 8) as e:
for i in range(8):
start = int(nmin + i * nrange/8)
end = int(nmin + (i + 1) * nrange/8)
e.submit(find_primes_in, start, end)
def main():
nmin = int(1e7)
nmax = int(1.05e7)
print("Sequential Prime Finder Starting")
sequential_prime_finder(nmin, nmax)
print("Threading Prime Finder Starting")
threading_prime_finder(nmin, nmax)
print("Processing Prime Finder Starting")
processing_prime_finder(nmin, nmax)
print("Thread Executor Prime Finder Starting")
thread_executor_prime_finder(nmin, nmax)
print("Process Executor Finder Starting")
process_executor_prime_finder(nmin, nmax)
main()
Sequential Prime Finder Starting
9.708213827005238 seconds
Threading Prime Finder Starting
9.81836523200036 seconds
Processing Prime Finder Starting
3.2467174359990167 seconds
Thread Executor Prime Finder Starting
10.228896902000997 seconds
Process Executor Finder Starting
2.656402041000547 seconds
Nenhuma das soluções acima realmente usou múltiplos núcleos no meu servidor GNU / Linux (onde eu não tenho direitos de administração). Eles apenas correram em um único núcleo. Usei a interface de nível inferior os.fork para desovar vários processos. Este é o código que funcionou para mim:
from os import fork
values = ['different', 'values', 'for', 'threads']
for i in range(len(values)):
p = fork()
if p == 0:
my_function(values[i])
break
import threading
import requests
def send():
r = requests.get('https://www.stackoverlow.com')
thread = []
t = threading.Thread(target=send())
thread.append(t)
t.start()