Como apagar as linhas duplicadas no servidor sql?
delete duplicate rows onde não existe nenhum unique row id?
a minha mesa é
col1 col2 col3 col4 col5 col6 col7
john 1 1 1 1 1 1
john 1 1 1 1 1 1
sally 2 2 2 2 2 2
sally 2 2 2 2 2 2
quero ficar com o seguinte depois da remoção duplicada:
john 1 1 1 1 1 1
sally 2 2 2 2 2 2
DELETE FROM table WHERE col1 IN (
SELECT id FROM table GROUP BY id HAVING ( COUNT(col1) > 1 )
)
15 answers
Eu gosto de ETI e ROW_NUMBER como os dois combinados nos permitem ver quais as linhas são apagadas( ou atualizadas), portanto basta mudar o DELETE FROM CTE... paraSELECT * FROM CTE:
WITH CTE AS(
SELECT [col1], [col2], [col3], [col4], [col5], [col6], [col7],
RN = ROW_NUMBER()OVER(PARTITION BY col1 ORDER BY col1)
FROM dbo.Table1
)
DELETE FROM CTE WHERE RN > 1
demonstração (o resultado é diferente; presumo que seja devido a um erro da sua parte)
COL1 COL2 COL3 COL4 COL5 COL6 COL7
john 1 1 1 1 1 1
sally 2 2 2 2 2 2
Este exemplo determina duplicados por uma única coluna col1 por causa do PARTITION BY col1. Se quiser incluir várias colunas, basta adicioná - las ao PARTITION BY:
ROW_NUMBER()OVER(PARTITION BY Col1, Col2, ... ORDER BY OrderColumn)
Preferia que o CTE removesse linhas duplicadas da tabela do servidor SQL
Recomendo vivamente que siga este artigo:: http://codaffection.com/sql-server-article/delete-duplicate-rows-in-sql-server/
Mantendo o original
WITH CTE AS
(
SELECT *,ROW_NUMBER() OVER (PARTITION BY col1,col2,col3 ORDER BY col1,col2,col3) AS RN
FROM MyTable
)
DELETE FROM CTE WHERE RN<>1
Sem manter o original
WITH CTE AS
(SELECT *,R=RANK() OVER (ORDER BY col1,col2,col3)
FROM MyTable)
DELETE CTE
WHERE R IN (SELECT R FROM CTE GROUP BY R HAVING COUNT(*)>1)
Sem usar CTE e ROW_NUMBER() pode apagar os registos apenas usando o grupo com a função MAX aqui está e o exemplo
DELETE
FROM MyDuplicateTable
WHERE ID NOT IN
(
SELECT MAX(ID)
FROM MyDuplicateTable
GROUP BY DuplicateColumn1, DuplicateColumn2, DuplicateColumn3)
DELETE from search
where id not in (
select min(id) from search
group by url
having count(*)=1
union
SELECT min(id) FROM search
group by url
having count(*) > 1
)
A Microsoft tem um guia vey ry puro sobre como remover duplicados. Check out http://support.microsoft.com/kb/139444
Em resumo, aqui está a maneira mais fácil de apagar duplicados quando você tem apenas algumas linhas para apagar:
SET rowcount 1;
DELETE FROM t1 WHERE myprimarykey=1;
o myprimarykey é o identificador da linha.
Eu ajustei o número de linhas para 1 porque só tinha duas linhas que foram duplicadas. Se eu tivesse 3 linhas duplicadas então eu teria configurado Número de linhas para 2 de modo que apaga os dois primeiros que vê e só deixa um na tabela t1.
Espero que ajude alguém.Por favor, Veja também a forma de eliminação abaixo.
Declare @table table
(col1 varchar(10),col2 int,col3 int, col4 int, col5 int, col6 int, col7 int)
Insert into @table values
('john',1,1,1,1,1,1),
('john',1,1,1,1,1,1),
('sally',2,2,2,2,2,2),
('sally',2,2,2,2,2,2)
Criou uma tabela de amostras chamada @table e carregou-a com dados indicados.

Delete aliasName from (
Select *,
ROW_NUMBER() over (Partition by col1,col2,col3,col4,col5,col6,col7 order by col1) as rowNumber
From @table) aliasName
Where rowNumber > 1
Select * from @table
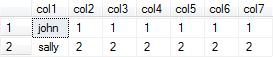
Nota: Se está a dar todas as colunas na parte Partition by, então order by não tem muito significado.
Eu sei, a pergunta é feita há três anos, e minha resposta é outra versão do que Tim postou, mas postar apenas incase é útil para qualquer um.
Seleccione o distinto [col1], [col2], [col3], [col4], [col5], [col6], [col7]
Em [newTable]
;
Vai ao explorador de objectos e apaga a mesa antiga.
Mudar o nome da nova tabela com o nome da velha tabela.
-- this query will keep only one instance of a duplicate record.
;WITH cte
AS (SELECT ROW_NUMBER() OVER (PARTITION BY col1, col2, col3-- based on what? --can be multiple columns
ORDER BY ( SELECT 0)) RN
FROM Mytable)
delete FROM cte
WHERE RN > 1
with myCTE
as
(
select productName,ROW_NUMBER() over(PARTITION BY productName order by slno) as Duplicate from productDetails
)
Delete from myCTE where Duplicate>1
A ideia de remover duplicados envolve
- a) proteger as linhas que não são duplicadas
- B) mantenha uma das muitas linhas que se qualificaram juntas como duplicadas.
Passo a Passo
- 1) primeiro identificar as linhas que satisfazem a definição de duplicado e introduzi-los na mesa temporária, diz # tableAll .
- 2) Seleccione as linhas não duplicadas(linhas simples) ou linhas distintas na tabela temp diz # tableUnique.
- 3) riscar o que não interessa na tabela de origem. duplicata.
- 4) Inserir na tabela de código todas as linhas de #tableUnique.
- 5) largar # tableAll e # tableUnique {[[9]}
Se você tem a capacidade de adicionar uma coluna à tabela temporariamente, esta foi uma solução que funcionou para mim:
ALTER TABLE dbo.DUPPEDTABLE ADD RowID INT NOT NULL IDENTITY(1,1)
Depois execute uma eliminação usando uma combinação de MIN e grupo por
DELETE b
FROM dbo.DUPPEDTABLE b
WHERE b.RowID NOT IN (
SELECT MIN(RowID) AS RowID
FROM dbo.DUPPEDTABLE a WITH (NOLOCK)
GROUP BY a.ITEM_NUMBER,
a.CHARACTERISTIC,
a.INTVALUE,
a.FLOATVALUE,
a.STRINGVALUE
);
Verifique se a eliminação foi efectuada correctamente:
SELECT a.ITEM_NUMBER,
a.CHARACTERISTIC,
a.INTVALUE,
a.FLOATVALUE,
a.STRINGVALUE, COUNT(*)--MIN(RowID) AS RowID
FROM dbo.DUPPEDTABLE a WITH (NOLOCK)
GROUP BY a.ITEM_NUMBER,
a.CHARACTERISTIC,
a.INTVALUE,
a.FLOATVALUE,
a.STRINGVALUE
ORDER BY COUNT(*) DESC
O resultado não deve ter linhas com uma contagem superior a 1. Finalmente, remover a coluna do rowid:
ALTER TABLE dbo.DUPPEDTABLE DROP COLUMN RowID;
Depois de tentar a solução sugerida acima, isso funciona para pequenas tabelas médias. Posso sugerir essa solução para mesas muito grandes. desde que funciona em iterações.
- largue todas as áreas de dependência do
LargeSourceTable - poderá encontrar as dependências usando o estúdio de gestão sql, carregue com o botão direito na tabela e carregue em "ver dependências"
- mudar o nome da tabela:
sp_rename 'LargeSourceTable', 'LargeSourceTable_Temp'; GO- Crie o
LargeSourceTablede novo, mas agora, adicione uma chave primária com todas as colunas que definem as duplicações adicionarWITH (IGNORE_DUP_KEY = ON) -
Por exemplo:
CREATE TABLE [dbo].[LargeSourceTable] ( ID int IDENTITY(1,1), [CreateDate] DATETIME CONSTRAINT [DF_LargeSourceTable_CreateDate] DEFAULT (getdate()) NOT NULL, [Column1] CHAR (36) NOT NULL, [Column2] NVARCHAR (100) NOT NULL, [Column3] CHAR (36) NOT NULL, PRIMARY KEY (Column1, Column2) WITH (IGNORE_DUP_KEY = ON) ); GO Crie de novo as vistas que deixou cair em primeiro lugar para a nova tabela criada
Agora, execute o seguinte script sql, você vai ver os resultados em 1.000.000 linhas por página, você pode alterar o número de linha por página para ver os resultados mais frequentemente.
Note que eu activei e desactivei o
IDENTITY_INSERTporque uma das colunas contém um incremental automático identificação, que também estou a copiar
SET IDENTITY_INSERT LargeSourceTable ON
DECLARE @PageNumber AS INT, @RowspPage AS INT
DECLARE @TotalRows AS INT
declare @dt varchar(19)
SET @PageNumber = 0
SET @RowspPage = 1000000
select @TotalRows = count (*) from LargeSourceTable_TEMP
While ((@PageNumber - 1) * @RowspPage < @TotalRows )
Begin
begin transaction tran_inner
; with cte as
(
SELECT * FROM LargeSourceTable_TEMP ORDER BY ID
OFFSET ((@PageNumber) * @RowspPage) ROWS
FETCH NEXT @RowspPage ROWS ONLY
)
INSERT INTO LargeSourceTable
(
ID
,[CreateDate]
,[Column1]
,[Column2]
,[Column3]
)
select
ID
,[CreateDate]
,[Column1]
,[Column2]
,[Column3]
from cte
commit transaction tran_inner
PRINT 'Page: ' + convert(varchar(10), @PageNumber)
PRINT 'Transfered: ' + convert(varchar(20), @PageNumber * @RowspPage)
PRINT 'Of: ' + convert(varchar(20), @TotalRows)
SELECT @dt = convert(varchar(19), getdate(), 121)
RAISERROR('Inserted on: %s', 0, 1, @dt) WITH NOWAIT
SET @PageNumber = @PageNumber + 1
End
SET IDENTITY_INSERT LargeSourceTable OFF
Outra forma de remover as linhas publicadas sem perder informação num passo é como a seguinte:
delete from dublicated_table t1 (nolock)
join (
select t2.dublicated_field
, min(len(t2.field_kept)) as min_field_kept
from dublicated_table t2 (nolock)
group by t2.dublicated_field having COUNT(*)>1
) t3
on t1.dublicated_field=t3.dublicated_field
and len(t1.field_kept)=t3.min_field_kept
DELETE FROM table WHERE col1 IN (
SELECT MAX(id) FROM table GROUP BY id HAVING ( COUNT(col1) > 1 )
)
Nota: poderá ter de a executar várias vezes para remover duplicado, uma vez que isto só irá apagar um conjunto de linhas duplicadas de cada vez.
Se conseguir encontrar o número de linhas duplicadas, por exemplo, tem uma linha n duplicada, então use este comando
SET rowcount n-1
DELETE FROM your_table
WHERE (spacial condition)
Para mais informações sugiro isto