Fazer uma lista plana da lista de listas em Python
pergunto-me se existe um atalho para fazer uma lista simples a partir da lista de listas em Python.
Posso fazer isso num loop, mas talvez haja um "one-liner"fixe? Tentei com a redução, mas tenho um erro.Código
l = [[1, 2, 3], [4, 5, 6], [7], [8, 9]]
reduce(lambda x, y: x.extend(y), l)
mensagem de erro
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 1, in <lambda>
AttributeError: 'NoneType' object has no attribute 'extend'
30 answers
flat_list = [item for sublist in l for item in sublist]
O que significa:
for sublist in l:
for item in sublist:
flat_list.append(item)
l é a lista para achatar.)
Aqui está a função correspondente:
flatten = lambda l: [item for sublist in l for item in sublist]
Para provas, como sempre, pode usar o Módulo timeit na Biblioteca Padrão:
$ python -mtimeit -s'l=[[1,2,3],[4,5,6], [7], [8,9]]*99' '[item for sublist in l for item in sublist]'
10000 loops, best of 3: 143 usec per loop
$ python -mtimeit -s'l=[[1,2,3],[4,5,6], [7], [8,9]]*99' 'sum(l, [])'
1000 loops, best of 3: 969 usec per loop
$ python -mtimeit -s'l=[[1,2,3],[4,5,6], [7], [8,9]]*99' 'reduce(lambda x,y: x+y,l)'
1000 loops, best of 3: 1.1 msec per loop
Explicação: os atalhos baseados em + (incluindo o uso implícito em sum) são, necessariamente, O(L**2) quando existem listas L -- como a lista de resultados intermédios continua a ficar mais longa, a cada step a new intermediate result list object gets all attributed, and all the items in the previous intermediate result must be copied over (as well as a few new ones added at the end). (Por simplicidade e sem perda de generalidade) digamos que você tenha L sublistas de eu itens cada: o primeiro que eu itens são copiados para trás e L-1 vezes, o segundo eu itens L-2 vezes, e assim por diante; número total de cópias é que eu vezes a soma de x para x de 1 a L excluídos, por exemplo, I * (L**2)/2.
A compreensão da lista apenas gera uma lista, uma vez, e copia cada item sobre (de seu local de residência original para a lista de resultados) também exatamente uma vez.
Pode usar itertools.chain():
>>> import itertools
>>> list2d = [[1,2,3],[4,5,6], [7], [8,9]]
>>> merged = list(itertools.chain(*list2d))
Ou, em Python >=2. 6, usar itertools.chain.from_iterable() o que não requer desempacotar a lista:
>>> import itertools
>>> list2d = [[1,2,3],[4,5,6], [7], [8,9]]
>>> merged = list(itertools.chain.from_iterable(list2d))
Esta abordagem é indiscutivelmente mais legível do que [item for sublist in l for item in sublist] e parece ser mais rápida também:
[me@home]$ python -mtimeit -s'l=[[1,2,3],[4,5,6], [7], [8,9]]*99;import itertools' 'list(itertools.chain.from_iterable(l))'
10000 loops, best of 3: 24.2 usec per loop
[me@home]$ python -mtimeit -s'l=[[1,2,3],[4,5,6], [7], [8,9]]*99' '[item for sublist in l for item in sublist]'
10000 loops, best of 3: 45.2 usec per loop
[me@home]$ python -mtimeit -s'l=[[1,2,3],[4,5,6], [7], [8,9]]*99' 'sum(l, [])'
1000 loops, best of 3: 488 usec per loop
[me@home]$ python -mtimeit -s'l=[[1,2,3],[4,5,6], [7], [8,9]]*99' 'reduce(lambda x,y: x+y,l)'
1000 loops, best of 3: 522 usec per loop
[me@home]$ python --version
Python 2.7.3
Nota do autor: isto é ineficiente. Mas divertido, porque os monads são fantásticos. Não é apropriado para a produção de código Python.
>>> sum(l, [])
[1, 2, 3, 4, 5, 6, 7, 8, 9]
Isto resume apenas os elementos iteráveis passados no primeiro argumento, tratando o segundo argumento como o valor inicial da soma (se não for dado, 0 é usado em vez disso e este caso dar-lhe-á um erro).
Porque você está somando listas aninhadas, você realmente obter {[[2]} como resultado de sum([[1,3],[2,4]],[]), que é igual a [1,3,2,4].
Note que só funciona em listas de listas. Para listas de listas de listas, você precisará de outra solução.
Testei a maioria das soluções sugeridas com perfplot (um projecto meu, essencialmente um invólucro em torno de timeit), e encontrei
list(itertools.chain.from_iterable(a))
Ser a solução mais rápida (se mais de 10 listas estiverem concatenadas).
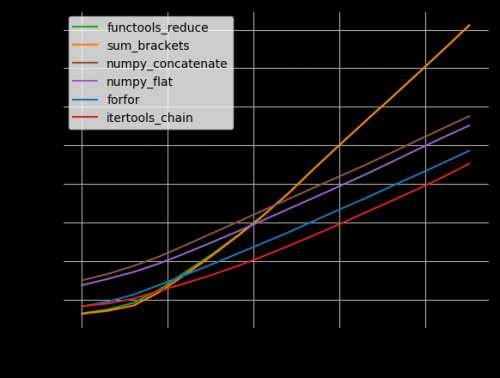
Código para reproduzir a parcela:
import functools
import itertools
import numpy
import operator
import perfplot
def forfor(a):
return [item for sublist in a for item in sublist]
def sum_brackets(a):
return sum(a, [])
def functools_reduce(a):
return functools.reduce(operator.concat, a)
def itertools_chain(a):
return list(itertools.chain.from_iterable(a))
def numpy_flat(a):
return list(numpy.array(a).flat)
def numpy_concatenate(a):
return list(numpy.concatenate(a))
perfplot.show(
setup=lambda n: [list(range(10))] * n,
kernels=[
forfor, sum_brackets, functools_reduce, itertools_chain, numpy_flat,
numpy_concatenate
],
n_range=[2**k for k in range(16)],
logx=True,
logy=True,
xlabel='num lists'
)
from functools import reduce #python 3
>>> l = [[1,2,3],[4,5,6], [7], [8,9]]
>>> reduce(lambda x,y: x+y,l)
[1, 2, 3, 4, 5, 6, 7, 8, 9]
O Método extend() no seu exemplo modifica x em vez de devolver um valor útil (o que reduce() espera).
Uma maneira mais rápida de fazer a versão reduce seria
>>> import operator
>>> l = [[1,2,3],[4,5,6], [7], [8,9]]
>>> reduce(operator.concat, l)
[1, 2, 3, 4, 5, 6, 7, 8, 9]
Aqui está uma abordagem geral que se aplica aos números , cordas, listas aninhadas e embalagens misturadas .
Código
from collections import Iterable
def flatten(items):
"""Yield items from any nested iterable; see Reference."""
for x in items:
if isinstance(x, Iterable) and not isinstance(x, (str, bytes)):
for sub_x in flatten(x):
yield sub_x
else:
yield x
yield from flatten(x) pode substituir for sub_x in flatten(x): yield sub_x
Demonstração
lst = [[1, 2, 3], [4, 5, 6], [7], [8, 9]]
list(flatten(lst)) # nested lists
# [1, 2, 3, 4, 5, 6, 7, 8, 9]
mixed = [[1, [2]], (3, 4, {5, 6}, 7), 8, "9"] # numbers, strs, nested & mixed
list(flatten(mixed))
# [1, 2, 3, 4, 5, 6, 7, 8, '9']
Referência
- esta solução é modificada a partir de uma receita em Beazley, D. E B. Jones. Receita 4.14, Python Cookbook 3rd Ed., O'Reilly Media Inc. Sebastopol, CA: 2013.
- encontrei uma anterior assim post, possivelmente a demonstração original.
Retiro o meu depoimento. sum não é o vencedor. Embora seja mais rápido quando a lista é pequena. Mas o desempenho degrada-se significativamente com listas maiores.
>>> timeit.Timer(
'[item for sublist in l for item in sublist]',
'l=[[1, 2, 3], [4, 5, 6, 7, 8], [1, 2, 3, 4, 5, 6, 7]] * 10000'
).timeit(100)
2.0440959930419922
A versão sum ainda está em execução por mais de um minuto e ainda não fez o processamento!
Para listas médias:
>>> timeit.Timer(
'[item for sublist in l for item in sublist]',
'l=[[1, 2, 3], [4, 5, 6, 7, 8], [1, 2, 3, 4, 5, 6, 7]] * 10'
).timeit()
20.126545906066895
>>> timeit.Timer(
'reduce(lambda x,y: x+y,l)',
'l=[[1, 2, 3], [4, 5, 6, 7, 8], [1, 2, 3, 4, 5, 6, 7]] * 10'
).timeit()
22.242258071899414
>>> timeit.Timer(
'sum(l, [])',
'l=[[1, 2, 3], [4, 5, 6, 7, 8], [1, 2, 3, 4, 5, 6, 7]] * 10'
).timeit()
16.449732065200806
Usando pequenas listas e tempo: número=1000000
>>> timeit.Timer(
'[item for sublist in l for item in sublist]',
'l=[[1, 2, 3], [4, 5, 6, 7, 8], [1, 2, 3, 4, 5, 6, 7]]'
).timeit()
2.4598159790039062
>>> timeit.Timer(
'reduce(lambda x,y: x+y,l)',
'l=[[1, 2, 3], [4, 5, 6, 7, 8], [1, 2, 3, 4, 5, 6, 7]]'
).timeit()
1.5289170742034912
>>> timeit.Timer(
'sum(l, [])',
'l=[[1, 2, 3], [4, 5, 6, 7, 8], [1, 2, 3, 4, 5, 6, 7]]'
).timeit()
1.0598428249359131
Porque é que usa extend?
reduce(lambda x, y: x+y, l)
operator.add! Quando você adiciona duas listas juntas, o termo correto para isso é concat, não adicionar. operator.concat é o que precisas de usar.
Se estás a pensar funcional, é tão fácil como isto.
>>> list2d = ((1, 2, 3), (4, 5, 6), (7,), (8, 9))
>>> reduce(operator.concat, list2d)
(1, 2, 3, 4, 5, 6, 7, 8, 9)
>>> list2d = [[1, 2, 3],[4, 5, 6], [7], [8, 9]]
>>> reduce(operator.concat, list2d)
[1, 2, 3, 4, 5, 6, 7, 8, 9]
Que tal performance::
>>> list2d = [[1, 2, 3],[4, 5, 6], [7], [8, 9]]
>>> %timeit list(itertools.chain.from_iterable(list2d))
1000000 loops, best of 3: 1.36 µs per loop
>>> list2d = ((1, 2, 3),(4, 5, 6), (7,), (8, 9))
>>> %timeit reduce(operator.concat, list2d)
1000000 loops, best of 3: 492 ns per loop
Se queres eliminar uma estrutura de dados onde não sabes a profundidade do ninho podes usar iteration_utilities.deepflatten1
>>> from iteration_utilities import deepflatten
>>> l = [[1, 2, 3], [4, 5, 6], [7], [8, 9]]
>>> list(deepflatten(l, depth=1))
[1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> l = [[1, 2, 3], [4, [5, 6]], 7, [8, 9]]
>>> list(deepflatten(l))
[1, 2, 3, 4, 5, 6, 7, 8, 9]
Para nivelar apenas um nível e se cada um dos itens for iterável você também pode usar iteration_utilities.flatten que por si só é apenas um invólucro fino À volta itertools.chain.from_iterable:
>>> from iteration_utilities import flatten
>>> l = [[1, 2, 3], [4, 5, 6], [7], [8, 9]]
>>> list(flatten(l))
[1, 2, 3, 4, 5, 6, 7, 8, 9]
Só para adicionar alguns temporizadores (baseado sobre a resposta de Nico Schlömer que não incluiu a função apresentada nesta resposta):

Os resultados mostram que, se o iterable contém apenas alguns interna iterables, em seguida, sum será mais rápido, no entanto, para uma longa iterables apenas o itertools.chain.from_iterable, iteration_utilities.deepflatten ou aninhado compreensão de ter um desempenho razoável com itertools.chain.from_iterable sendo o mais rápido (como já notado por Nico Schlömer).
from itertools import chain
from functools import reduce
from collections import Iterable # or from collections.abc import Iterable
import operator
from iteration_utilities import deepflatten
def nested_list_comprehension(lsts):
return [item for sublist in lsts for item in sublist]
def itertools_chain_from_iterable(lsts):
return list(chain.from_iterable(lsts))
def pythons_sum(lsts):
return sum(lsts, [])
def reduce_add(lsts):
return reduce(lambda x, y: x + y, lsts)
def pylangs_flatten(lsts):
return list(flatten(lsts))
def flatten(items):
"""Yield items from any nested iterable; see REF."""
for x in items:
if isinstance(x, Iterable) and not isinstance(x, (str, bytes)):
yield from flatten(x)
else:
yield x
def reduce_concat(lsts):
return reduce(operator.concat, lsts)
def iteration_utilities_deepflatten(lsts):
return list(deepflatten(lsts, depth=1))
from simple_benchmark import benchmark
b = benchmark(
[nested_list_comprehension, itertools_chain_from_iterable, pythons_sum, reduce_add,
pylangs_flatten, reduce_concat, iteration_utilities_deepflatten],
arguments={2**i: [[0]*5]*(2**i) for i in range(1, 13)},
argument_name='number of inner lists'
)
b.plot()
1 Disclaimer: eu sou o autor dessa biblioteca
Considere instalar o more_itertools Pacote.
> pip install more_itertools
A empresa dispõe de uma implementação para flatten (fonte , das receitas de itertools):
import more_itertools
lst = [[1, 2, 3], [4, 5, 6], [7], [8, 9]]
list(more_itertools.flatten(lst))
# [1, 2, 3, 4, 5, 6, 7, 8, 9]
A partir da versão 2.4, você pode achatar iterables mais complicados, aninhados com more_itertools.collapse (fonte , contribuição da abarnet.
lst = [[1, 2, 3], [4, 5, 6], [7], [8, 9]]
list(more_itertools.collapse(lst))
# [1, 2, 3, 4, 5, 6, 7, 8, 9]
lst = [[1, 2, 3], [[4, 5, 6]], [[[7]]], 8, 9] # complex nesting
list(more_itertools.collapse(lst))
# [1, 2, 3, 4, 5, 6, 7, 8, 9]
A razão pela qual a sua função não funcionou: a extensão estende a matriz no local e não a devolve. Você ainda pode devolver x de lambda, usando algum truque:
reduce(lambda x,y: x.extend(y) or x, l)
Nota: O extend é mais eficiente do que o + nas listas.
Uma má característica da função do Anil acima é que requer que o utilizador indique sempre manualmente o segundo argumento como sendo uma lista vazia []. Este deve ser um padrão. Devido à forma como os objetos Python funcionam, estes devem ser definidos dentro da função, não nos argumentos.
Aqui está uma função de trabalho:
def list_flatten(l, a=None):
#check a
if a is None:
#initialize with empty list
a = []
for i in l:
if isinstance(i, list):
list_flatten(i, a)
else:
a.append(i)
return a
Teste:
In [2]: lst = [1, 2, [3], [[4]],[5,[6]]]
In [3]: lst
Out[3]: [1, 2, [3], [[4]], [5, [6]]]
In [11]: list_flatten(lst)
Out[11]: [1, 2, 3, 4, 5, 6]
def flatten(l, a):
for i in l:
if isinstance(i, list):
flatten(i, a)
else:
a.append(i)
return a
print(flatten([[[1, [1,1, [3, [4,5,]]]], 2, 3], [4, 5],6], []))
# [1, 1, 1, 3, 4, 5, 2, 3, 4, 5, 6]
A seguir parece-me mais simples:
>>> import numpy as np
>>> l = [[1, 2, 3], [4, 5, 6], [7], [8, 9]]
>>> print (np.concatenate(l))
[1 2 3 4 5 6 7 8 9]
matplotlib.cbook.flatten() trabalhará para listas aninhadas, mesmo que elas nidifiquem mais profundamente do que o exemplo.
import matplotlib
l = [[1, 2, 3], [4, 5, 6], [7], [8, 9]]
print(list(matplotlib.cbook.flatten(l)))
l2 = [[1, 2, 3], [4, 5, 6], [7], [8, [9, 10, [11, 12, [13]]]]]
print list(matplotlib.cbook.flatten(l2))
Resultado:
[1, 2, 3, 4, 5, 6, 7, 8, 9]
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13]
Average time over 1000 trials of matplotlib.cbook.flatten: 2.55e-05 sec
Average time over 1000 trials of underscore._.flatten: 4.63e-04 sec
(time for underscore._)/(time for matplotlib.cbook) = 18.1233394636
Código simples para underscore.py ventoinha de pacote
from underscore import _
_.flatten([[1, 2, 3], [4, 5, 6], [7], [8, 9]])
# [1, 2, 3, 4, 5, 6, 7, 8, 9]
Resolve todos os problemas achatados (nenhum item da lista ou nidificação complexa)
from underscore import _
# 1 is none list item
# [2, [3]] is complex nesting
_.flatten([1, [2, [3]], [4, 5, 6], [7], [8, 9]])
# [1, 2, 3, 4, 5, 6, 7, 8, 9]
Você pode instalar underscore.py com pip
pip install underscore.py
def flatten(alist):
if alist == []:
return []
elif type(alist) is not list:
return [alist]
else:
return flatten(alist[0]) + flatten(alist[1:])
Podes usar o numpy :flat_list = list(np.concatenate(list_of_list))
Se estiver disposto a desistir de uma pequena quantidade de velocidade para um visual mais limpo, então pode usar numpy.concatenate().tolist() ou numpy.concatenate().ravel().tolist():
import numpy
l = [[1, 2, 3], [4, 5, 6], [7], [8, 9]] * 99
%timeit numpy.concatenate(l).ravel().tolist()
1000 loops, best of 3: 313 µs per loop
%timeit numpy.concatenate(l).tolist()
1000 loops, best of 3: 312 µs per loop
%timeit [item for sublist in l for item in sublist]
1000 loops, best of 3: 31.5 µs per loop
Podes descobrir mais aqui no docs numpy.concatenato e numpy.ravel
flat_list = []
for i in list_of_list:
flat_list+=i
Este código também funciona bem, uma vez que apenas estende a lista até ao fim. Embora seja muito semelhante, mas só tem um para o loop. Assim, tem menos complexidade do que adicionar 2 para loops.
A solução mais rápida que encontrei (para uma lista grande de qualquer maneira):
import numpy as np
#turn list into an array and flatten()
np.array(l).flatten()
test = ['591212948',
['special', 'assoc', 'of', 'Chicago', 'Jon', 'Doe'],
['Jon'],
['Doe'],
['fl'],
92001,
555555555,
'hello',
['hello2', 'a'],
'b',
['hello33', ['z', 'w'], 'b']]
Onde métodos como flat_list = [item for sublist in test for item in sublist] não funcionaram. Então, eu inventei a seguinte solução para 1 + Nível de sublistas
def concatList(data):
results = []
for rec in data:
if type(rec) == list:
results += rec
results = concatList(results)
else:
results.append(rec)
return results
E o resultado
In [38]: concatList(test)
Out[38]:
Out[60]:
['591212948',
'special',
'assoc',
'of',
'Chicago',
'Jon',
'Doe',
'Jon',
'Doe',
'fl',
92001,
555555555,
'hello',
'hello2',
'a',
'b',
'hello33',
'z',
'w',
'b']
from typing import List
def flatten(l: list) -> List[int]:
"""Flatten an arbitrary deep nested list of lists of integers.
Examples:
>>> flatten([1, 2, [1, [10]]])
[1, 2, 1, 10]
Args:
l: Union[l, Union[int, List[int]]
Returns:
Flatted list of integer
"""
return [int(i.strip('[ ]')) for i in str(l).split(',')]
A resposta aceite não funcionou para mim ao lidar com listas baseadas em texto de comprimentos variáveis. Aqui está uma abordagem alternativa que funcionou para mim.
l = ['aaa', 'bb', 'cccccc', ['xx', 'yyyyyyy']]
Resposta aceite que fez nãotrabalhar:
flat_list = [item for sublist in l for item in sublist]
print(flat_list)
['a', 'a', 'a', 'b', 'b', 'c', 'c', 'c', 'c', 'c', 'c', 'xx', 'yyyyyyy']
Nova solução proposta que fez trabalhar para mim:
flat_list = []
_ = [flat_list.extend(item) if isinstance(item, list) else flat_list.append(item) for item in l if item]
print(flat_list)
['aaa', 'bb', 'cccccc', 'xx', 'yyyyyyy']
Você pode evitar chamadas recursivas para a pilha usando uma estrutura de dados de pilha real muito simplesmente.
alist = [1,[1,2],[1,2,[4,5,6],3, "33"]]
newlist = []
while len(alist) > 0 :
templist = alist.pop()
if type(templist) == type(list()) :
while len(templist) > 0 :
temp = templist.pop()
if type(temp) == type(list()) :
for x in temp :
templist.append(x)
else :
newlist.append(temp)
else :
newlist.append(templist)
print(list(reversed(newlist)))
def make_list_flat (l):
flist = []
flist.extend ([l]) if (type (l) is not list) else [flist.extend (make_list_flat (e)) for e in l]
return flist
a = [[1, 2], [[[[3, 4, 5], 6]]], 7, [8, [9, [10, 11], 12, [13, 14, [15, [[16, 17], 18]]]]]]
flist = make_list_flat(a)
print (flist)
A saída é
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18]
Isto funciona de uma primeira maneira profunda. A recursão desce até encontrar um elemento não-listado, estendendo então a variável local flist e, em seguida, rola de volta para o pai. Sempre que flist é devolvido, ele é estendido para o pai está na compreensão da lista. Portanto, na raiz, uma lista plana é retornada.
O acima cria várias listas locais e devolve-as que são usadas para estender a lista dos pais. Eu acho que o caminho para isso pode ser criar um gloabl flist, como em baixo.
a = [[1, 2], [[[[3, 4, 5], 6]]], 7, [8, [9, [10, 11], 12, [13, 14, [15, [[16, 17], 18]]]]]]
flist = []
def make_list_flat (l):
flist.extend ([l]) if (type (l) is not list) else [make_list_flat (e) for e in l]
make_list_flat(a)
print (flist)
A saída é novamente
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18]
Embora neste momento não tenha a certeza sobre a eficiência.
Nota : a seguir aplica-se ao Python 3. 3+ porque usa yield_from. six é também um pacote de terceiros, embora seja estável. Alternadamente, você poderia usar sys.version.
No caso de obj = [[1, 2,], [3, 4], [5, 6]], todas as soluções aqui são boas, incluindo a compreensão da lista e itertools.chain.from_iterable.
No entanto, considere este caso um pouco mais complexo:
>>> obj = [[1, 2, 3], [4, 5], 6, 'abc', [7], [8, [9, 10]]]
- um elemento,
6, é apenas um escalar; não é iterável, para que as rotas acima falhem aqui. - um elemento,
'abc', is tecnicamente iterável (todos osstrsão). No entanto, lendo um pouco entre as linhas, você não quer tratá-lo como tal--você quer tratá-lo como um único elemento. - o elemento final,
[8, [9, 10]]é ele próprio um iterável aninhado. Compreensão básica da lista echain.from_iterableapenas extrair "1 nível abaixo."
Pode remediar isto da seguinte forma:
>>> from collections import Iterable
>>> from six import string_types
>>> def flatten(obj):
... for i in obj:
... if isinstance(i, Iterable) and not isinstance(i, string_types):
... yield from flatten(i)
... else:
... yield i
>>> list(flatten(obj))
[1, 2, 3, 4, 5, 6, 'abc', 7, 8, 9, 10]
Iterable, um ABC de itertools, mas também quer garantir que (2)o elemento é Não " tipo cadeia."
Limpei o exemplo @Deleet
from collections import Iterable
def flatten(l, a=[]):
for i in l:
if isinstance(i, Iterable):
flatten(i, a)
else:
a.append(i)
return a
daList = [[1,4],[5,6],[23,22,234,2],[2], [ [[1,2],[1,2]],[[11,2],[11,22]] ] ]
print(flatten(daList))
Exemplo: https://repl.it/G8mb/0